代码托管从业者 Git 指南
0. 前言
六七年前,机缘巧合进入了代码托管行业,做过基于 Git 支持 SVN 客户端接入,做过 Git 代码托管平台分布式,做过 Git 代码托管读写分离,做过 Git 代码托管高可用,所幸学到了一些知识,积累了一些经验,这或许对已在或者即将进入代码托管行业的朋友有些帮助,便分享出来,权当是经验之谈,希望读的人有些许收获。
1. Git 的发展历史
1.1 版本控制系统的发展历史
版本控制系统历史悠久,最早的开源的版本控制系统可以追溯到几乎与 C 语言同时诞生的 Source Code Control System (SCCS),作者来自于著名的贝尔实验室的 Marc J. Rochkind,他于 1973 年发布了 SCCS 的初始版本,SCCS 的寿命悠久,直到 2007 年再没有人维护而终结。SCCS 本质上是一种 Local Only 版本控制系统,在网络快速发展的时代,几乎是无法跟上历史的脚步,也就只能消亡,同类型的 RCS 虽然维护至今,却鲜有人问津。
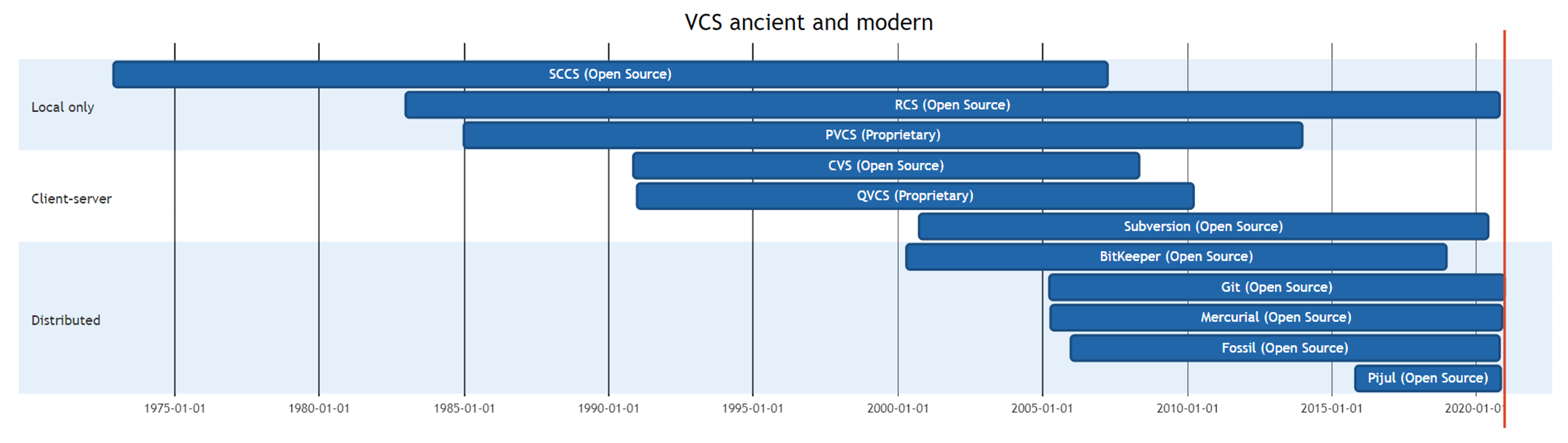
常见版本控制系统清单:

1986 年诞生的 CVS 是一款真正的自由软件,使用 GPL 协议发布,有一个有趣的事实是,CVS 是 RCS 的前端,也就是说,CVS 将 RCS 从 Local Only 变成了 Client-Server 版本控制系统。随着 2000 年 Apache Subversion 诞生,CVS 的市场快速萎缩,到了 2008 年 CVS 不再维护,集中式版本控制系统渐渐的也只剩 Subversion 在维护了。
最早的分布式版本控制系统是 1992 年诞生的 Sun WorkShop TeamWare,但它并没有发展的很好,从 2000 年到 2007 年,分布式版本控制系统如雨后春笋一样冒了出来,2005 年诞生的 Git 和 Mercurial 幸运的流传开来,时至今日,Git 终于在版本控制领域风头正劲,独占鳌头。
1.2 Git 的发展史
2005 年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了 Linux 内核社区免费使用 BitKeeper 的权利。Linus Torvalds 花了十天时间编写了 Git 的第一个版本,Git 的故事由此展开。
Git 原本只能在 Linux 上运行,随着开源社区的参与,Git 也逐渐能在各个平台上运行,在 Windows 上,最初有两个方案,一个是让 Git 在 Cygwin 的环境下编译,Cygwin 是 Windows 上的 POSIX 兼容层,但 Cygwin 的缺陷是需要带一大堆的 DLL。另一个方案是 msysgit,基于 MSYS 运行时,MYSY 是更小的 POSIX 兼容环境。到了 2015 年,msysgit 不再维护,主要开发者基于 MSYS2 环境推出了 Git for Windows。而 MSYS2 的核心运行时基于 Cygwin 进行了定制。值得一提的是,在 Git for Windows 中,Git 命令并不是基于 MSYS2 运行时,而是原生的 Windows 程序,到了今天我们已经可以使用 Visual C++ 编译 Git 源码了,Git for Windows 的维护者 Johannes Schindelin 加入了微软后,在 Windows 上使用 Git 的体验也越来越好。
2008 年 11 月 Shawn O. Pearce 写下了 libgit2 的第一个提交,2009 年 9 月,Shawn 写下了 JGit 的第一个提交,libgit2/jgit 被代码托管平台,Git 客户端广泛使用,比如 Github 使用 libgit2 的 Ruby 绑定 rugged 提供页面读写存储库能力。遗憾的是 Shawn 已经离开这个世界两年多了。
回顾 Git 的一些大事件,2008 年 Github 诞生,Github 是最成功的代码托管平台,几乎以一己之力带来了 Git 的繁荣。2008 年 BitBucket 诞生,最初 BitBucket 还支持 Mercurial,到了 2020 年则不再支持 Mercurial。2011 年 Gitlab 诞生,而国内的 Gitee 也是基于 Gitlab 发展而来的。2014 年 CODING 成立,国内国外代码托管平台百花齐放。2018 年,微软花费 75 亿美元收购 Github,大家才猛然发现,基于 Git 的代码托管平台已经有了这样大的价值。
Git 是一个充满活力的版本控制系统,每一年,Git 的开发者们都在将他们新的知识,经验实施到 Git 之中,2018 年 5 月,在谷歌工作的 Git 开发者们发布了 Git Wire Protocol,这解决了 Git 协议中最低效的部分,到了 2020 年 10 月,Git 实验性的支持 SHA256 哈希算法,在 SHA1 被破解几年后,我们终于可以在 Git 中尝试淘汰 SHA1 了。
Git 的发展必然会挤占其他版本控制系统份额,随着 Git 的越来越流行,更多的项目也从其他的版本控制系统迁移到 Git 上来:
- 编译器基础设施 LLVM 从 SVN 迁移到 Git
- FreeBSD 从 SVN 迁移到 Git
- GCC (仍处于迁移过程中) 从 SVN 迁移到 Git
- Windows 源码(已经迁移到 Git,使用 VFS for Git 技术)
- VIM 迁移到 Github
- OpenJDK 从 Mercurial 迁移到 Git
2016 年,Git 诞生11年之后,BitKeeper 宣布采用 Apache 2.0 许可协议开源,如果再回到 2005 年,BitKeeper 又会做出怎样的抉择呢?
2. Git 的存储原理
对于代码托管从业人员来说,只了解 Git 的使用并不足以去参与代码托管平台服务的开发,架构的优化,所以了解 Git 的一些原理则非常必要。
2.1 Git 的目录结构
首先,我们可以去了解一下 Git 存储库的目录结构,Git 存储库分为常规存储库和 Bare (裸)存储库,普通用户从远程克隆下来的存储库或者本地初始化的存储库大多是常规存储库,这类存储库和特定的工作区相关联;另一类是没有工作区的存储库,就是裸存储库,在代码托管平台的服务器上面,存储库几乎都是以裸存储库的方式存储的。对于常规存储库而言,其存储库真正的路径是工作区根目录下的 .git 文件夹,或者 .git 文件指向的目录,后者通常用于 Git 子模块。
我们知道了 Git 存储库的位置,就可以查看存储库的目录结构,下面是一个查看存储库的截图。
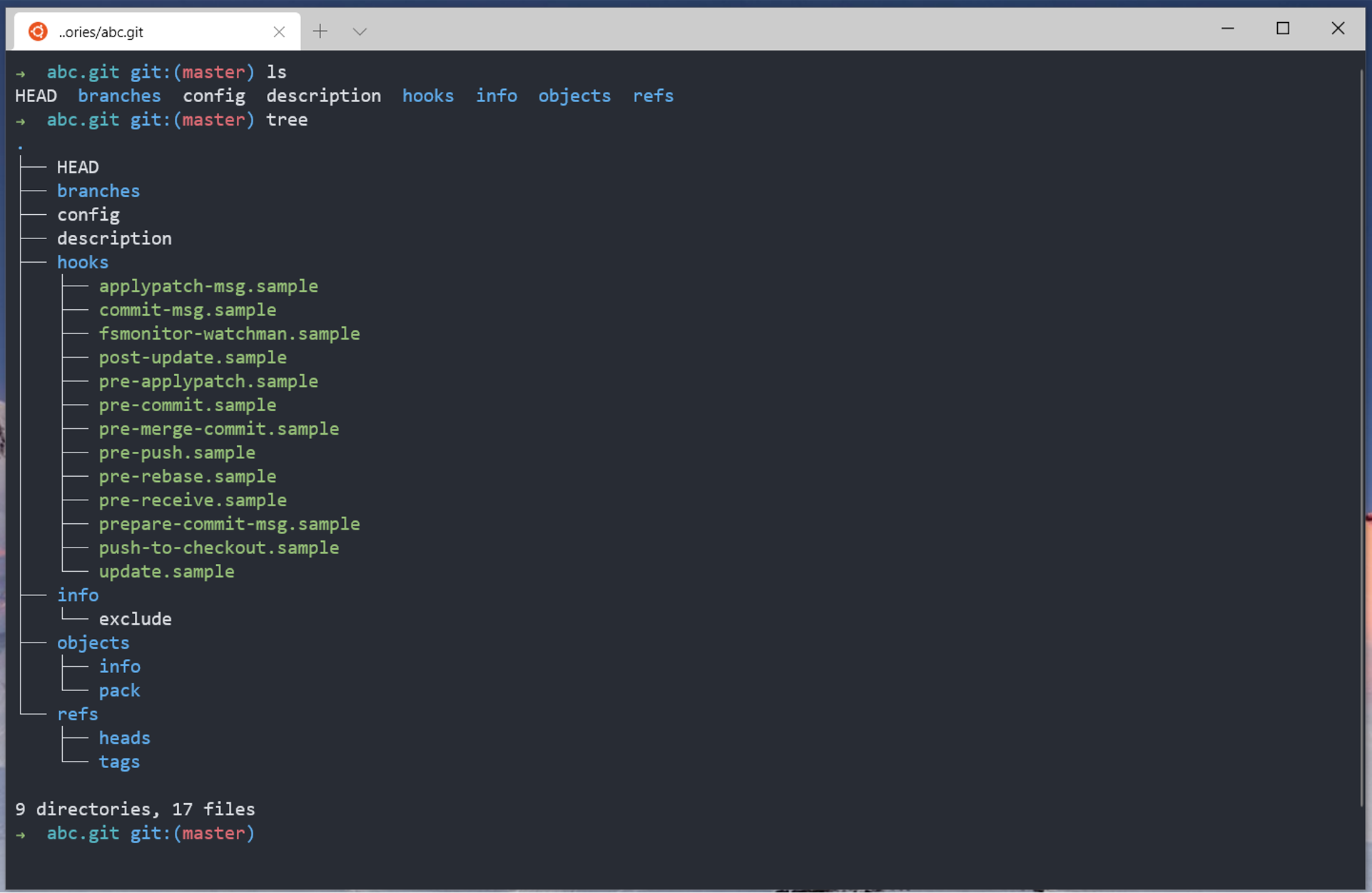
不同的目录具备不同的作用,大致如下:
| 路径 | 属性 | 作用 | 备注 |
|---|---|---|---|
| HEAD | R |
存储当前检出的引用或者提交 ID | 在远程服务器上用于展示默认分支 |
| config | R |
存储库配置 | 存储库配置优先级高于用户配置,用户配置优先级高于系统配置 |
| branches | D |
deprecated |
|
| description | R |
depracated |
|
| hooks | D |
Git 钩子目录,包括服务端钩子和客户端钩子 | 当设置了 core.hooksPath 时,则会从设置的钩子目录查找钩子 |
| info | D |
存储库信息 | dump 协议依赖,但目前 dump 协议已经无人问津 |
| objects | D |
存储库对象存储目录 | |
| refs | D |
存储库引用存储目录 | |
| packed-refs | R |
存储库打包引用存储文件 | 该文件可能不存在,运行 git pack-refs 或者 git gc 后出现 |
在这些目录或者文件中,最重要的是 objects 和 refs 这只需要两个目录的数据就可以重建存储库了。在 objects 目录下,Git 对象可能以松散对象也可能以打包对象的形式存储:
| 路径 | 描述 |
|---|---|
objects/[0-9a-f][0-9a-f] |
松散对象存储目录,最多有 256 个这样的子目录 |
objects/pack |
打包对象目录,除了打包对象,还有打包对象索引,多包索引等 |
objects/info |
存储存储库扩展信息 |
objects/info/packs |
哑协议依赖 |
objects/info/alternates |
存储库对象借用技术 |
objects/info/http-alternates |
存储库对象借用,用于 HTTP fetch |
Git 在实现其复杂功能的时候还会创建一些其他目录,更详细的细节可以查阅:Git Repository Layout。
2.2 Git 对象的存储
Git 的对象可以按照松散对象的格式存储,也可以按照打包对象的格式存储,用户将文件纳入版本控制时,Git 会将文件的类型标记为 blob,将文件长度和 \x00 以及文件内容合并在一起计算 SHA1 哈希值后,使用 Deflate 压缩,存储到存储库的 objects 目录下,路径匹配正则为 objects\/[0-9a-f]{2}\/[0-9a-f]{38}$ ,当然,如果使用 SHA256 则应该匹配 objects\/[0-9a-f]{2}\/[0-9a-f]{62}$,松散对象的空间布局如下:
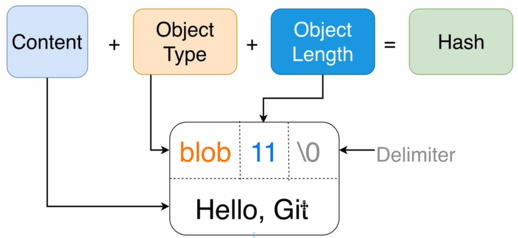
Git 使用的 Deflate 是 Phil Katz 为 PKZIP 创建的压缩算法,也是使用最广泛的压缩算法之一,其变体 GZIP 也被广泛用于 POSIX 文件压缩和 HTTP 压缩,git 命令行,libgit2 目前依赖 zlib 提供 deflate 算法,jgit 则使用 Java 提供的 deflate 实现,Golang 则在 compress/zlib 包中提供 deflate 支持,但算法实现在 compress/flate,严格来说 Git 使用的是 deflate 的 zlib 包装,比如我们使用 zlib 创建 zip 压缩包时会使用 -15 作为 WindowBits,而在创建 GZIP 时会使用 31 作为 WindowBits,在 Git 中,则会使用 15 作为 WindowBits。
在 Git 中,除了有 blob 对象,还有 commit ,tag,以及 tree ,commit 对象存储了用户的提交信息,tree 顾名思义,存储的是目录结构。下面是一个 commit 对象的内容:
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
First commit
下面是 tree 对象的内容:
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
解析松散对象非常容易,我们只需要使用能够解析 zlib 的库就可以完成这一操作,这里有一个例子可以参考 https://gist.github.com/fcharlie/2dde5a491d08dbc45c866cb370b9fa07。
想要了解更多的 Git 对象的细节可以参考: Git Internals - Git Objects。
站在文件系统的角度上看,数量巨大的小文件性能通常会急剧下降,而松散对象就是这样的小文件,Git 的解决方案是引入了打包文件,打包文件就是将多个松散对象依次存储到打包文件的存储空间之中,相关的布局如下:
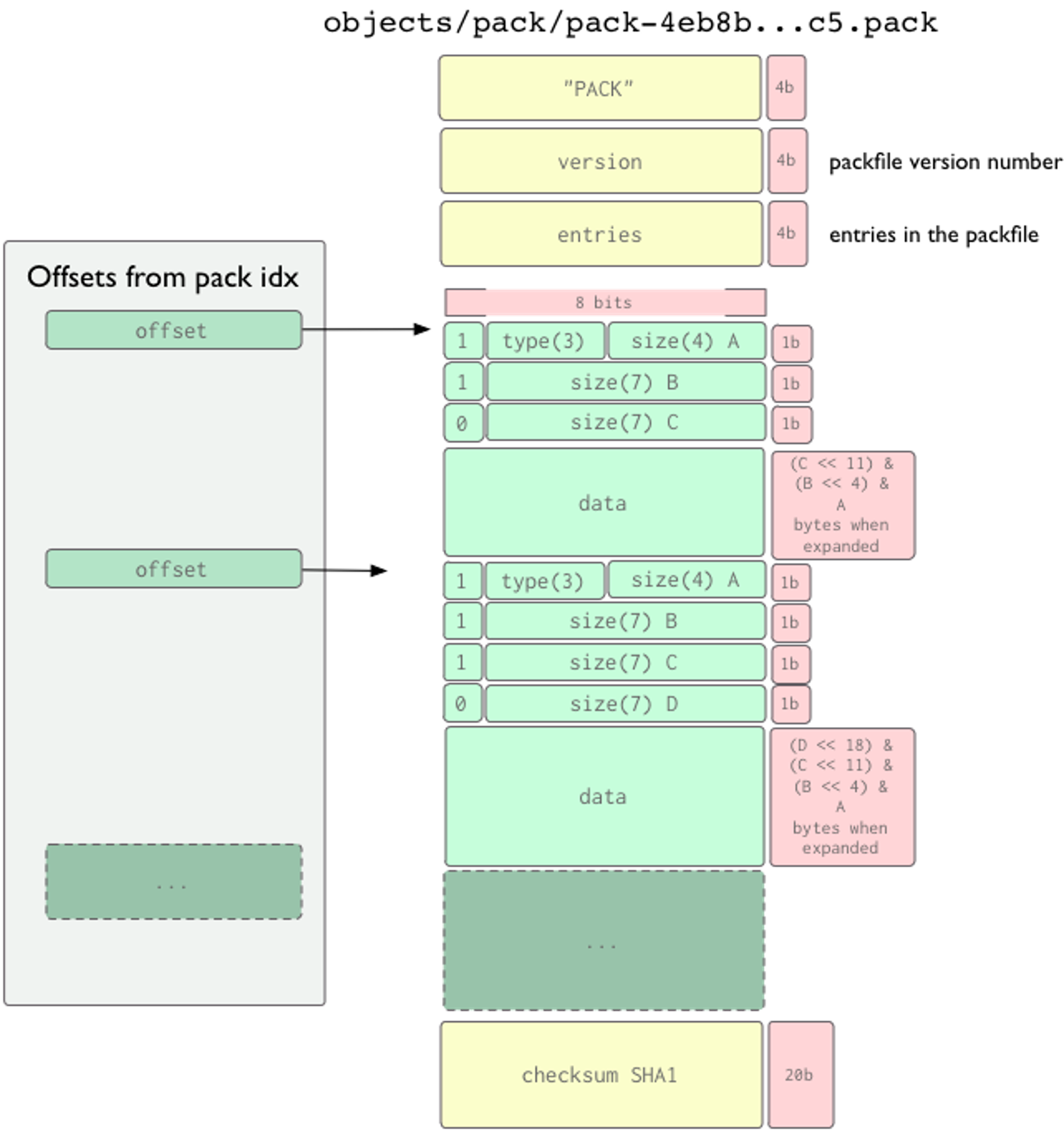
Pack 文件的路径正则为 objects\/pack\/pack-[0-9a-f]{40}.pack$,当存储库使用 SHA256 哈希算法时,相应的路径正则为objects\/pack\/pack-[0-9a-f]{64}.pack$,Pack 文件的魔数是 'P','A','C','K',随后的 4字节是版本信息,版本可以为 2,也可以为 3,后者是 SHA256 支持的前提。我们在读取 Pack 文件版本的时候需要注意,Git 使用网络字节序存储数据,也就是常说的大端,目前 Windows 全部使用小端字节序,macOS/iOS 等也是这样,Linux x86/AMD64 也是小端,ARM/ARM64 事实上也使用小端,使用大端的平台非常少。版本后紧接着是 4 字节的数字,用于表示这个包中有多少个 Git 对象,4字节意味着单个 Pack 中最多只能有 232-1 个 Git 对象。接下来的事情就稍微复杂一些,Git 存储对象时使用 3-bit表示对象类型,(n-1)*7+4 bit 表示文件长度,这种机制主要是支持大于 4G 的文件和支持 OBJ_OFS_DELTA ,也就是说,尽管 Git 是基于快照的,但是在 pack 文件中,我们依然可以看到一些对象使用差异存储,这样的好处是节省空间,坏处就是查看对象复杂度上升,因此,Git 会倾向于将历史久远的用 OBJ_OFS_DELTA 存储,以降低影响,不管怎么说,都是权衡利弊,保证存储和读取的平衡。最后是 20 字节的 checksum SHA1,当然如果是 SHA-256 存储库,则需要使用 SHA-256 计算 checksum。
上图一目了然,如果没有其他措施,我们要在 Pack 文件中查找某个对象是非常难的,所幸这个问题一开始就被重视了,在 pack 文件的同级目录下存在文件后缀名为 .idx 的文件,就是 Pack Index,其布局如下:
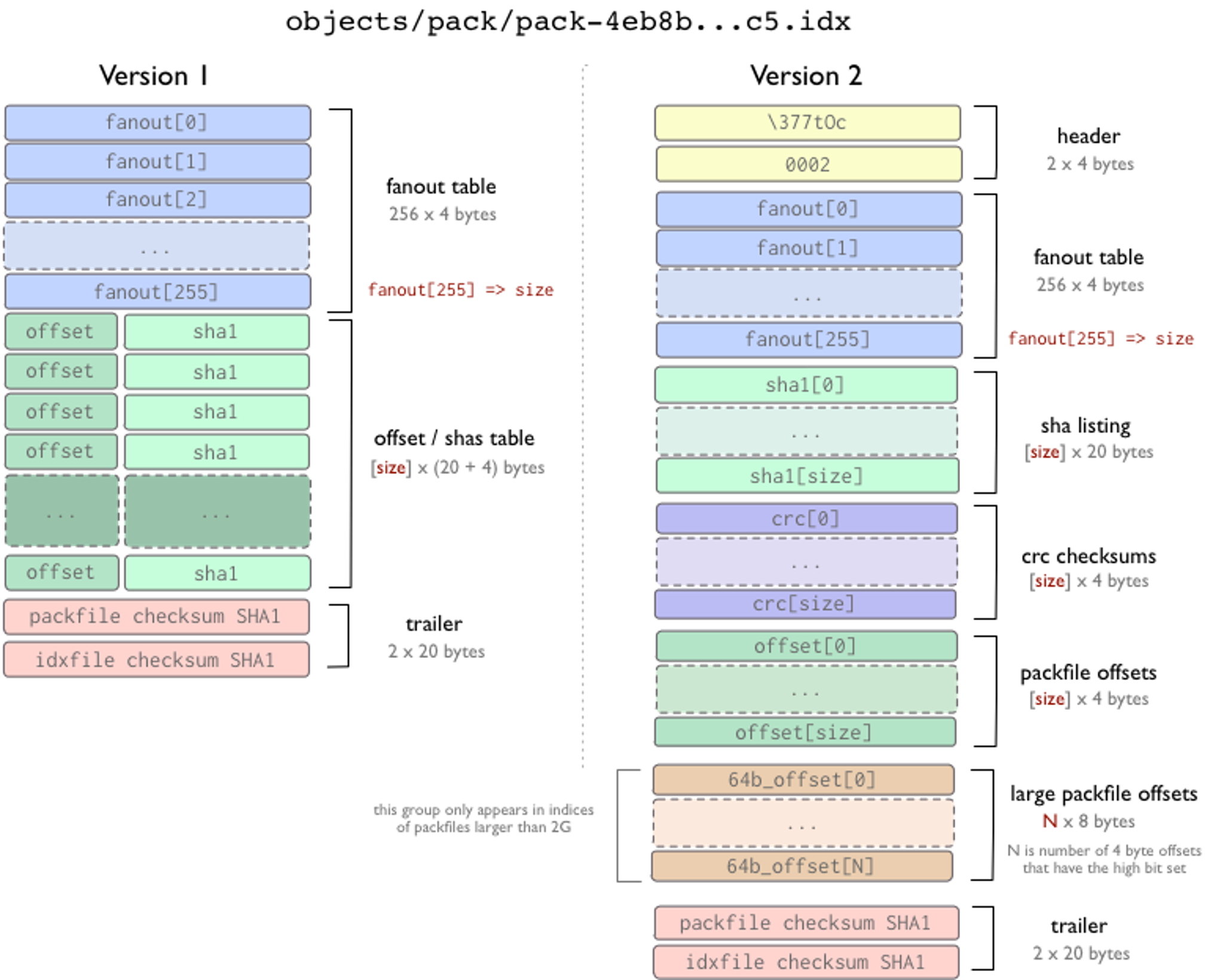
版本1的 Pack-Index 现在已经很难见到,原因很简单,不支持 Pack 文件大于 4 GB,版本2格式非常有趣,魔数为 '\377','t','O','c',第二个 4 字节就是版本信息,随后是 256 * 4 的扇区表,0~254 分别表示前缀从 0x00~0xFE 的对象数量,而 fanout[255] 则表示所有对象的数量,随后对象 ID 按字典排序到 sha listing,紧接着是相应的 crc checksums,然后是 packfile offsets,packfile offsets 是 4 字节的,这并不能支持 Pack 大于 4 GB。而后续的 large packfile offsets 则支持了 Pack 大于 4 GB。当 4byte offset 最高位是1时说明需要从 large packfile offsets 读取长度。
Pack Index 文件很好的解决了 Pack 文件的随机读取的问题,按照其特性,我们在查找 Git 对象时,使用二分法查找,最多 8 次就可以在找到对象在 pack 中的偏移,进一步读取文件。
但如果 Pack 文件数量特别多时,还是会遇到查找对象性能较多,微软在将 Windows 源码迁移到 Git 后也遇到了这个问题,后来在微软工程师的努力下,multi-pack-index (MIDX) 出现了,存在多个 Pack 文件时,MIDX 便可以加快 Git 对象的查找。
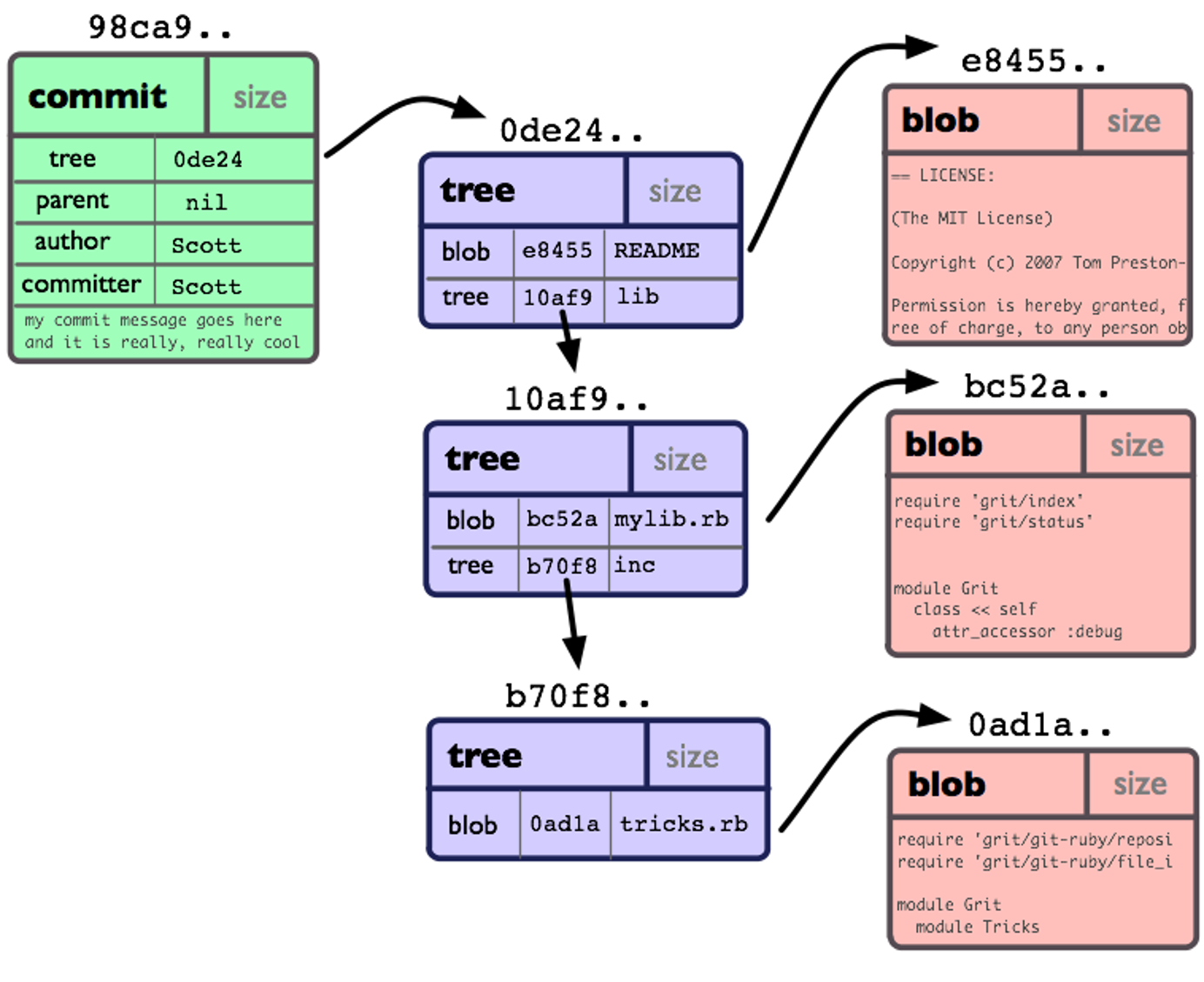
既然我们已经对 Git 的存储有了个简单的认识,那么要找到某个文件也不在话下,分支对应了一个提交,提交有一个 ID,我们可以在松散对象或者打包对象中找到该 ID,然后获得提交的内容,找到 tree 后,按照路径一级级的往下找,找到路径匹配的 blob,该 blob 解压后的内容就是文件的原始内容,一个简单的流程如下:
对于引用而言,通常存储在 refs 目录下,和松散对象一样,这种机制可能存在性能问题,因此,在运行 git gc 后,引用会被打包到 packed-refs 文件中集中管理,为了加快引用的查询,引用名会使用字典排序,git 同样会使用二分法查找在 packed-refs 中查找引用。尽管查找引用的速度非常快,但面对 Android 这样引用数量巨大的项目,git 依然会显得心有余而力不足,这需要人们设计一个好的方案解决其性能问题。
2.3 Git 存储原理的运用
了解到 Git 的存储原理后,我们可以基于其原理做一些有趣的事情,比如我们要快速的找到存储库中存在哪些大文件,我们可以通过分析 Pack Index,将文件的偏移按照递减的顺序排列,依次相减就可以知道某一对象在 Pack 中占据的大致大小,这样就可以实现大文件的检测。这种机制要比从 Pack 中依次读取文件大小高效的多,同时对于平台而言,尽管存在一些误差,但这种方案却是十分经济有效的。
另外,在实现代码托管平台存储库快照的功能时,可以通过研究存储库引用的存储机制,利用引用名称空间实现存储库的快照,相对于直接克隆快照的方案,存储空间的节省是非常大的。
3. Git 的传输协议
对于现代版本控制系统而言,传输协议与代码托管平台的关系更为密切,只要支持了该版本控制系统的传输协议才意味着,平台支持这个版本控制系统,要支持 Git,代码托管平台也就需要了解 git 的传输协议。
3.1 传输协议的发展
和版本控制系统的不断发展类似,Git 的传输协议也是在不断的发展,以适应新的情况。谈到 Git 传输协议,我们最常用的是智能协议,除了智能协议,git 还有本地协议,哑协议(Dump Protocol),以及有线协议(Wire Protocol/v2 Protocol)。本地协议通常指通过文件系统路径或者 file:// 协议路径访问本机上的存储库的协议,该协议本质上是通过命令调用将其他目录的存储库拷贝到指定目录,这类协议的用处较少,其中有一个细节需要讲清楚,基于文件系统路径的克隆,也就是非 file:// 协议克隆,会将源存储库的对象,这里通常是 .pack 文件通过硬链接的方式共享,这实际上是利用了 git 对象的只读特性,也就是只能删除和新增而不能修改,另外,两个目录并不在同一个分区则不支持硬链接,也就不能使用硬链接共享对象。
哑协议旨在为服务端没有 git 服务时提供只读的 Git Over HTTP 访问支持,正因为不支持写操作,目前几乎所有的公共代码托管平台均已经不在支持哑协议了。
既然哑协议不堪重任,那么也只能另起炉灶,设计一个好的协议了,这就有了智能协议,但随着 git 被广泛使用,智能协议也显得有一些先天性缺陷,这不就有了有线传输协议。
3.2 智能传输协议
git 目前主要支持的网络协议有三种,分别是 http(s)://,ssh://,git:// 无论哪种协议,拉取实质上都是 git-fetch-pack/git-upload-pack 的数据交换,推送都是 git-send-pack/git-receive-pack 的数据交换,在 2018 年以前,均是采用智能传输协议,我们可用使用 Wireshark 这样的工具抓包分析其传输流程,也可以使用 GIT_CURL_VERBOSE=2 GIT_TRACE_PACKET=2 这样设置环境变量后运行相关命令调试 Git,在 Windows 中可以使用我编写的包管理器 baulk 中的命令运行器 baulk-exec 运行相关命令,如:
baulk-exec GIT_CURL_VERBOSE=1 GIT_TRACE_PACKET=2 git ls-remote https://github.com/baulk/baulk.git
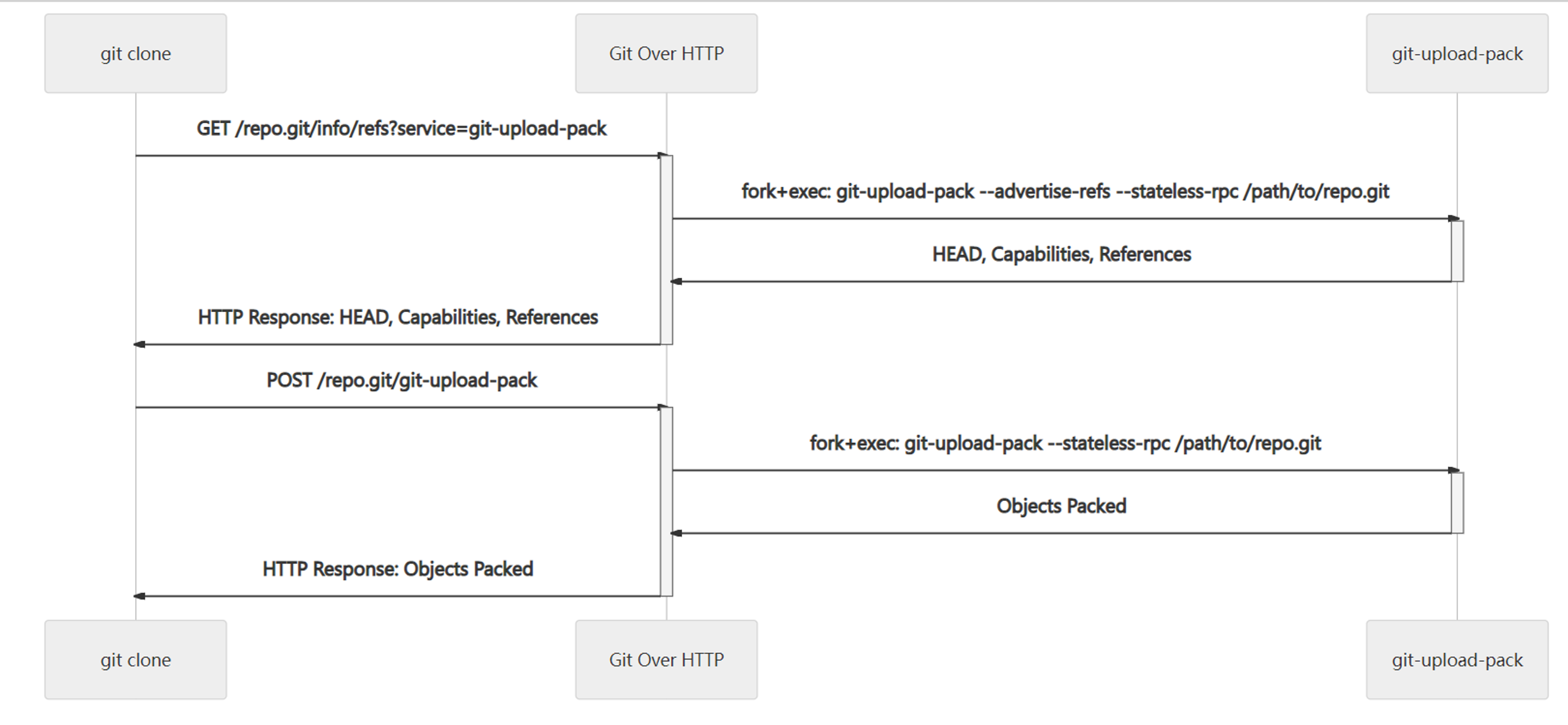
分析协议的方法已经有了,我们就可以轻易的知道智能协议的流程,以 http(s):// 为例,我们把传输的第一个步骤叫做引用发现,客户端根据存储库的 URL 使用 GET 请求到 /repo.git/info/refs?service=git-upload-pack 这样的地址,服务端则以 --advertise-refs --stateless-rpc 这样的参数启动 git-upload-pack,该命令启动后将存储库目前的 HEADcommitID,存储库支持的 capabilities,以及 HEAD 对应的 symref 以及所有的引用名及其 commitID 返回给客户端,客户端根据这些信息,以及本地的存储库已经存在的对象清点出需要的 want 和存在的 have commitID,然后通过 POST /repo,git/git-upload-pack 发送给服务端,服务端通过执行 git-upload-pack --stateless-rpc /path/to/repo.git 将打包好的对象返回给客户端,待客户端清点好对象,传输就结束了了,对于 git pull 请求还需要将更新的文件检出到工作目录。
这里需要注意,实施 Git Over HTTP 服务器时,git 客户端需要在 POST 请求响应最开始添加 001e# service=git-upload-pack\n0000,另外我们还需要正确的设置 Content-Type,服务端处理POST 请求时,请求体可能使用 gzip 编码,需要解压缩处理。
推送的传输协议流程类似,但服务变为 git-receive-pack,相关的流程如下:
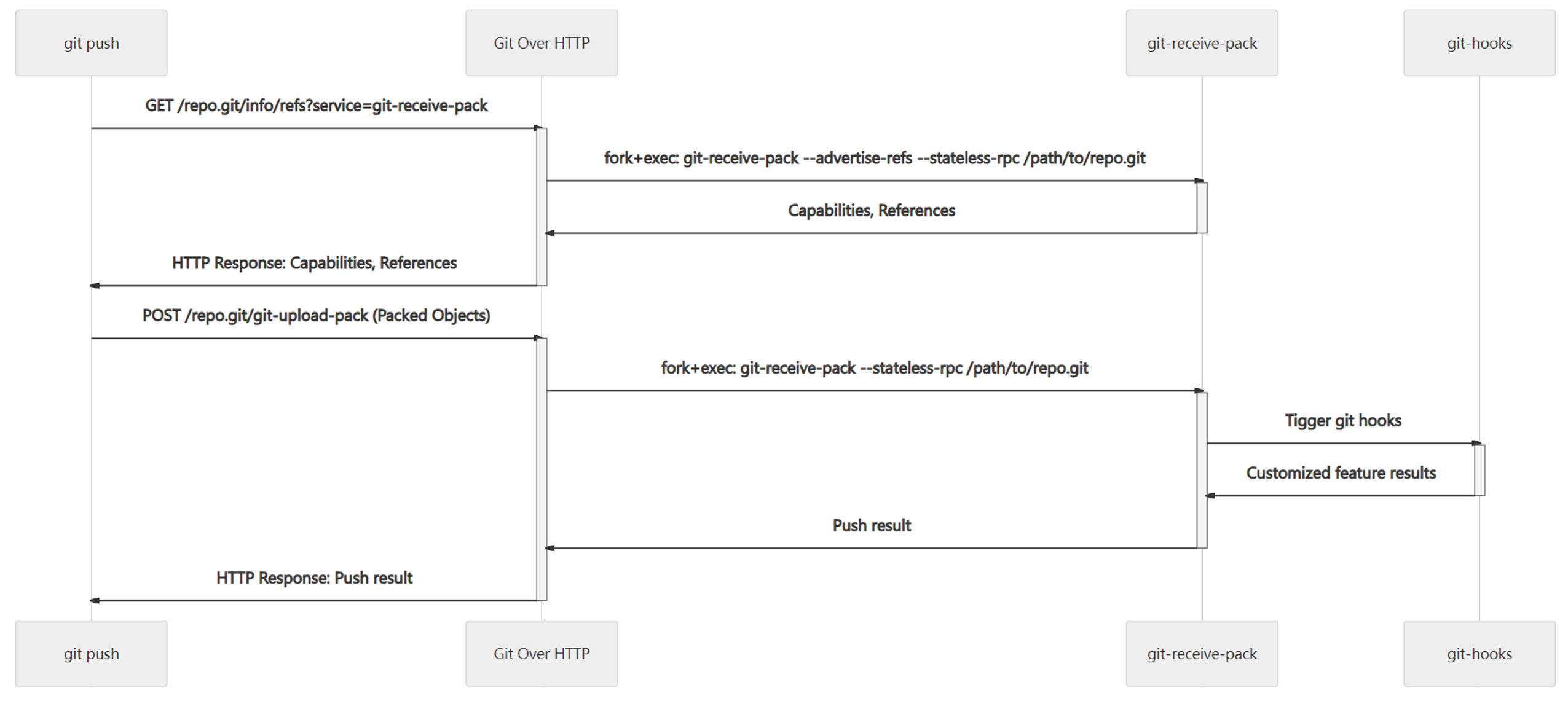
在推送时,git 协议本身的权限验证机制极其有限,一些分支权限控制等安全功能基本上只能通过钩子实现,而钩子的标准错误实际上也会被 git 命令行捕获作为响应返回给客户端,如果客户端的 git 恰好运行在 Windows Terminal、Mintty,iTerm 等等终端中,那么我们就可以将一些带有信息以彩色的形式输出给用户,这些信息使用 ANSI 转义的。
ssh:// 协议和 git:// 协议同样支持智能传输协议,实现起来只需要把为客户端连接和 git-upload-pack/git-receive-pack 的标准输入和输出建立数据交换的通道即可。在实施 Git Over SSH SSH 服务器时,像 Gitlab 会直接使用 OpenSSH,但 OpenSSH 可定制性有限,在分布式 Git 平台上需要实现模拟的 git-upload-pack/git-receive-pack 这样的命令,效率较低。像 Github 早期使用了 libssh 实现了 Git Over SSH 服务,BitBucket 使用了 Apache Mina SSHD,还有一些平台使用了 Golang crypto/ssh,无论采用什么样的技术,都应该经过慎重考虑,是否契合平台的架构,维护成本是否合适等等。在实施 Git Over TCP (git://) 服务器时,只需要解析第一个 pktline 数据包即可,git:// 协议简单,表达能力有限,没有足够的权限验证,公有云除了 Github 其他平台使用的较少,但我在设计读写分离和高可用时,会优先考虑使用 git:// 协议作为内部传输协议以降低内部负载。
ssh:// 协议和 git:// 协议可以支持数据的多次往返,而 http(s):// 协议只能是 Request-->Response 这样的一个来回,不同的来回实际上状态已经丢失,所以需要指定为 State Less 也就是无状态。
智能协议虽然非常简单,但我们在 Git Over HTTP 上支持 shallow clone 时却不得不注意一些细节,在协商 commit deepin 时,客户端和服务端都在等待对方的响应,这时候,我们只能通过提前关闭服务端的标准输入中断一方的等待,这就是智能传输协议的大问题,HTTP 传输实现复杂,不支持扩展。另外随着 VFS for Git 这样技术的诞生,使得一个问题浮现在公众面前:“巨型存储库如何优化克隆”。VFS for Git 重新设计了传输协议更显得智能传输协议在这上面显得尤为不足。
3.3 有线传输协议
Google 开发者的思路是,通过一个特殊的环境变量开关控制协议的切换,从外表看,传输协议仍然是几组命令的输入输出交换,但从内在看,新的传输协议更像是利用低级别的命令实现功能的扩展。我们依然可以使用上面的调试方法分析 git 有线协议的传输流程,在新的协议中,服务端先返回了版本信息,支持的命令,过滤器,对象格式等等,客户端再次发送请求需要使用 ls-refs 发现引用,然后是 fetch 命令(一下截图中没有这一操作)获得数据。
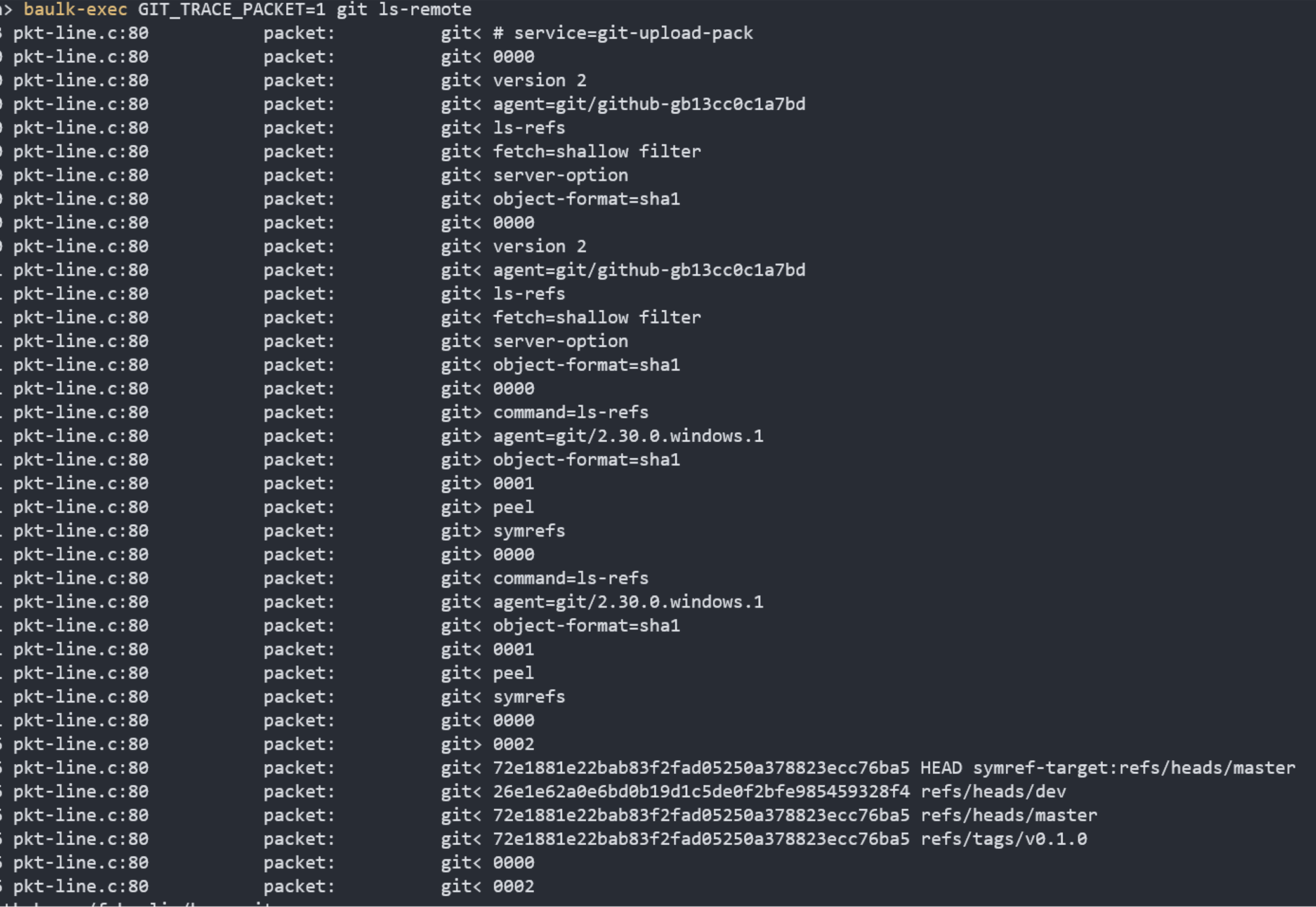
实施 Git 有线传输协议非常简单,只需要升级 git 命令,检测客户端请求是否为 GIT_PROTOCOL=2,然后以环境变量 GIT_PROTOCOL=2 启动上述命令即可,在我们的博客《Git Wire 协议杂谈》 也有介绍。
Git Wire 协议是 Git 的一次大的改变,在协议中添加了命令,filter 等机制,有效的解决了传输协议中最 低效的部分,增强了可扩展性,比如我们使用部分克隆时,需要添加 blob filter,即我不需要我就可以不下载文件,支持 SHA256 时,告诉服务端,我需要 object-format=sha256,这为 git 增加了无限可能。目前 git 的部分克隆,SHA256 存储库都依赖有线传输协议。
实际上集中式版本控制系统 SVN 早就利用子命令扩展了协议能力,SVN 协议使用 ABNF 描述协议,要比 git 的有线协议解析起来复杂一些。
Git Wire 协议虽然是一个重大的变革,但同时也是一个新事物,也就意味着可能存在一些设计和实现上的不足,没有经历足够的考验,我们在支持该协议的时候就需要特别注意测试和验证。比如我就反馈过,当用户基于 v2 协议使用错误的 --shallow-since 克隆存储库时,服务端在传输流程结束后,客户端并不会正确的退出,Github Issue: Protocol v2: The wrong –shallow-since time format causes git to wait indefinitely,最近,我们在使用 v2 for git 协议浅表克隆时,也发现了了类似的问题,问题出现在服务端,现象是 git-upload-pack 无限等待,该问题差一点照成了严重的事故。
3.4 Git 数据的交换
我们了解了 Git 的存储结构和传输协议后,再建立宏观上的 Git 数据交换映像就容易的多,我们对 Git 的操作实际上是发生在三个区域,工作区是我们实质上修 改,添加,删除文件的地方,通过 git add/commit/checkout 等命令,我们就将工作区的文件纳入版本 管理了,通过 git push/fetch 等命令,就将本地存储库和远程建立了关联。这里需要注意,git pull 实际 上是 git fetch+ git checkout(没有 merge 的情况下),大致如下图:
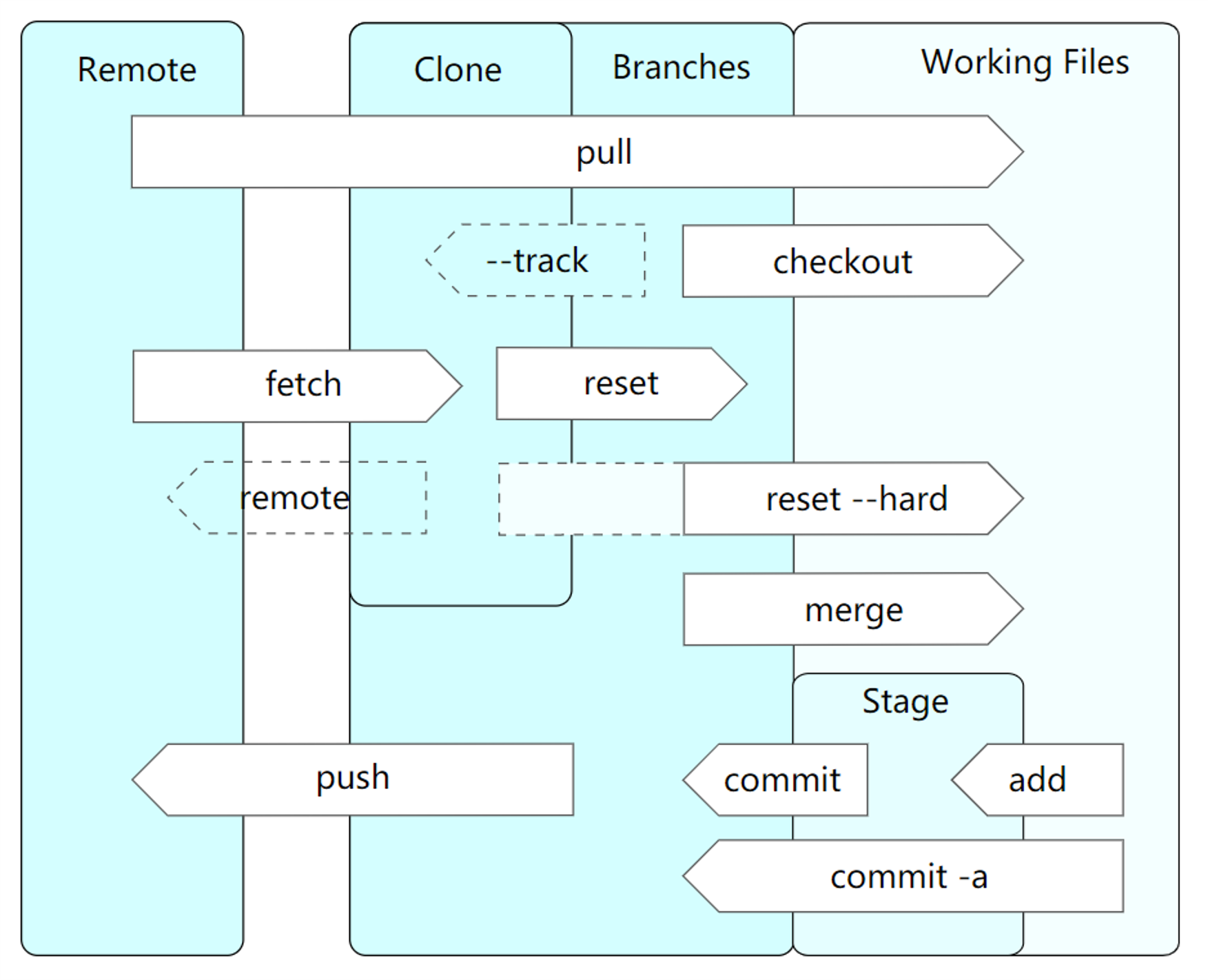
4. 大型 Git 代码托管平台的关键问题
随着平台规模的增长,代码托管从业人员也会遇到一些问题难以解决,在我职业生涯中同样如此,解决问题的过程是艰辛的,一些经验被积累下来,分享给读者,或许可以使人有所增益。去年年底,我曾经写过一篇文章:《性能,可扩展性和高可用 - 大型 Git 代码托管平台的关键问题》,文章的内容与本节内容相似,这里重新回顾一下。
4.1 大型存储库的优化
目前国内 IT 行业版本控制系统都在往 Git 迁移,一些大型企业,软件源码历史悠久,存储的文件各种各样,在迁移到 Git 时,体积巨大的存储库给代码托管平台带来了压力,首先映入眼前的是,从其他版本控制系统迁移到 git 耗时太长。
git 在安装了 svn 的前提下,支持 git svn 命令访问 svn 仓库,从 svn 仓库迁移到 git 的逻辑很简单,就是从 Rev0 开始,递归的创建 git 提交,如果这个存储库历史悠久,提交特别多,文件特别多,那么转换耗时将非常长。网络上也一种优化方案,直接在 svn 中央存储库,通过解析存储库元数据,直接在上面创建 git 提交,这种方案的耗时可能是原本的数十分之一。KDE 团队维护的 svn-all-fast-export aka svn2git 就是其中一款。
转移到 git 后,如果存储库包含很多的二进制文件,存储库体积巨大,那么用户拉取的时间还是会很长,一种解决方案是将不同的数据分离,也就是将体积大的二进制文件,通过 git 扩展 git lfs 追踪,从源码中排除,通过这种措施,存储库的体积减小,平台的压力降低,而这些大文件可以存储到其他的设备上,比如对象存储,利用 CDN 优化,也就能提升用户的体验,实现 git lfs 服务器可以参考我之前的博客《Git LFS 服务器实现杂谈》。
如果存储库小文件特别多,这个时候 Git LFS 的作用反而没有那么大了,Git LFS 并不存在打包机制,也没有压缩,如果大量文件使用 Git LFS 跟踪,那么 HTTP 请求数会变得非常多和传输时间也会特别长。微软在将 Windows 源码迁移到 git 做技术选型便遇到了问题,Windows 源码数百 GB,引用数量数十万,这些传统方案和 Git LFS 完全不能解决。于是微软的开发者推出了 VFS of Git 用来解决这个问题,简单来说,VFSforGit 的手段是只获得浅表 commit 以及相应的 tree 对象,然后在文件系统建立虚拟文件,也就是用户空间文件系统 Filesystem in Userspace (FUSE) 创建占位符文件,但向这种文件发起 IO 操作时,驱动会触发 VFSforGit 客户端取请求远程服务器,获得这些文件,在 Windows 上 VFSforGit 的 FUSE 使用了 NTFS 重解析点特性,其 TAG 为 IO_REPARSE_TAG_PROJFS,微软前员工 Saeed Noursalehi(现已加入 Facebook)曾写过一些 VFSforGit 的文章,比如 《Git at Scale》以及《Git Virtual File System Design History》,大家有兴趣可以看一下。VFSforGit 惊艳的架构也吸引了 Github 的注意,当时 Github 还未被 Microsoft 收购,Github 创建了 Linux projected filesystem library 项目试图在 Linux 上创建类似 Windows 平台的 projfs,以支持 VFSforGit 在 Linux 上运行,但该项目一直没有被完成。
VFSforGit 的设计是独树一帜的,但也很难推广开来,目前除了 Microsoft 的 Azure,其他平台几乎都没有支持 VFSforGit,最重要的原因就是 git 客户端支持难度高。正因如此,在 VFSforGit 诞生后 git 的一些开发者提议在 git 中实现部分克隆,经过几年的努力,终于支持部分克隆,该方案和 VFSforGit 类似,使用有线传输协议的 filter 机制,实现一个 blob filter 过滤掉 blob,与 VFSforGit 存在差异的是,没有 FUSE 加成,终究依然是使用有限,至于是否能够有其他手段提升部分克隆的实用性,还有待 Git 贡献者们进一步的努力了。
最近,Git 贡献者还增加了 Packfile URIs 设计,该方案旨在将对象通过 CDN 存储,然后客户端根据返回的地址请求到合适的 CDN 下载存储库对象,该方案仍处于早期,还有许多细节要处理,最终能做到什么程度有待观察。
2021-07-05 更新,在代码托管领域,我们将单一大库称之为 Monorepo,显然,Microsoft 的 Windows 源代码存储库算得上,Microsoft 基于 Git 支持了单一大库;在使用 Perforce 多年后,Google 开发了自己的 Piper(相关阅读),Facebook 更喜欢使用 Mercurial,他们在 Github 上开源了 Monorepo 解决方案,使用 Rust 编写的,带有 Mercurial 特色的 EdenSCM,EdenSCM 和 VFSforGit 类似之处就是 EdenFS 在 Linux/macOS 上使用 FUSE,在 Windows 上使用 Projected FS 来提高用户的检出效率,做到按需拉取,按需下载。
4.2 代码托管平台伸缩性
大型代码托管平台面临的另一个问题则是系统的伸缩性,在架构上具备良好的伸缩性则意味着平台能做到多大的规模,比如 Gitea/Gogs 这种倾向于单节点的开源代码托管平台要做到大型分布式代码托管平台就麻烦得多,而 Gitlab 则更容易搭建分布式可扩展的代码托管平台。
在讨论伸缩性之前,我们要解释一下分布式文件系统为什么不适合大型代码托管平台。
- Git 的计算压力并没有随着分布式文件系统的扩展性而分摊。
- 分布式文件系统很难解决 Git 小文件的问题,特别是小文件带来的系统调用,IO 问题。
- 分布式文件系统反而会带来平台内部网络数据的消耗,文件的元数据,以及文件的数据。
- 国内外厂商的生产事故历历在目。
当了解到分布式文件系统不合适之后,我们也就只能采用笨办法,分片,将存储库分布在不同的存储节点,git 命令也在这个节点上运行,这样无论是计算还是 I/O 都能够通过存储节点的扩展实现扩容,这就是 Git 目前最主要的分布式解决方案。
通过这样的方案实现平台的伸缩性时,还需要解决一些分布式环境常见的问题,比如存储库的分布,存储库队列等等,当然这些都有可用的方案,在这里也就没有必要细说了。
4.4 主从同步,读写分离和多写高可用架构探讨
无论是公共代码托管平台还是私有化部署的代码托管服务,当代平台发展到一定程度,高可用这个问题就会被反复提及,分布式系统的架构设计难度较高,与传统的单机服务有很大的差别,而 git 代码托管平台分布式系统与普通的分布式系统有更大的差异,高可用的设计不仅要吸纳主流的分布式系统的架构经验,还需要迎合 git 的特性,另外还需要考虑到架构的经济性。
首先我们先看一下分布式大型代码托管平台的简易架构(下图的架构是精简版本,与实际架构还是有一些差距),从下图我们可以看到,用户的 git 请求实际上并不是直接请求到存储节点上的 git 服务,而是通过代理服务转发过去,这些代理服务通过路由模块获得存储库位于那个存储节点,从架构上讲,这些代理服务都可以做到无状态,从过部署多个服务副本再在前端入口添加负载均衡健康检查可以很好的做到这些代理服务的高可用,但这个架构也意味着存储节点上的存储库并不能支持高可用。
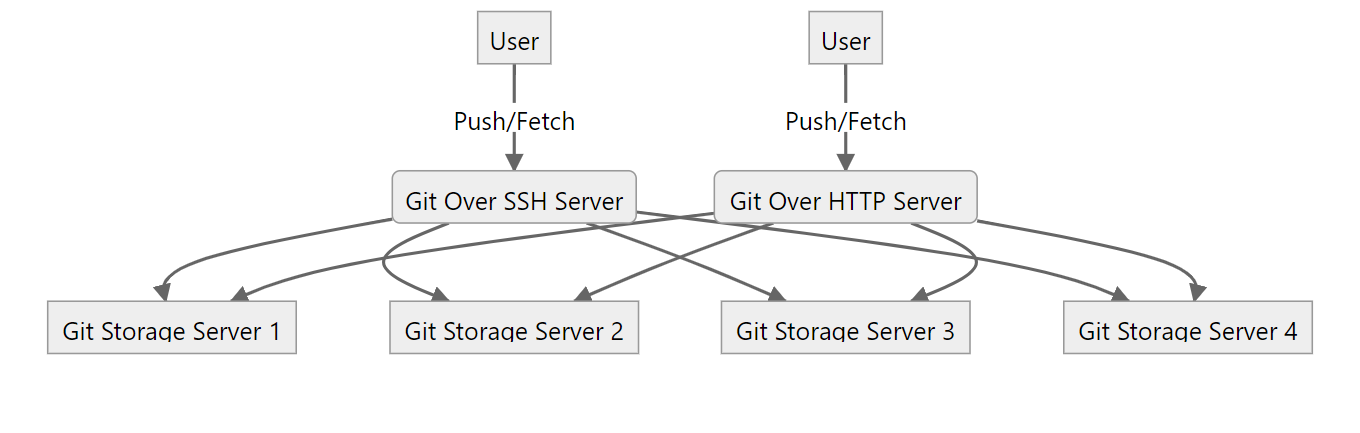
存储库要支持高可用,应该在不同的存储节点上都存在副本,在一个副本所在的节点无法正常提供服务时,需要其他副本所在的节点能够顶上来提供服务,高可用这些副本要始终保持一致,如果不一致,在切换的时候就会出现数据紊乱,这显然是不符合用户期望的。高可用可分为主从同步高可用,以及读写分离高可用,还有同时多写高可用(多写高可用),设计一个简单的主从同步高可用系统,我们首先的保证存储库的一致性,这里我们可以通过 git hooks 触发存储库实时同步,存储库副本分布在不同的节点,在用户推送代码后,被更新的存储库副本及时将数据通过内部传输协议同步到其他副本。早期 Github 使用 DRDB 实现同步,目前大多使用 git 传输协议实现同步,我个人更偏好于实现自定义的 git:// 提供存储库同步功能。
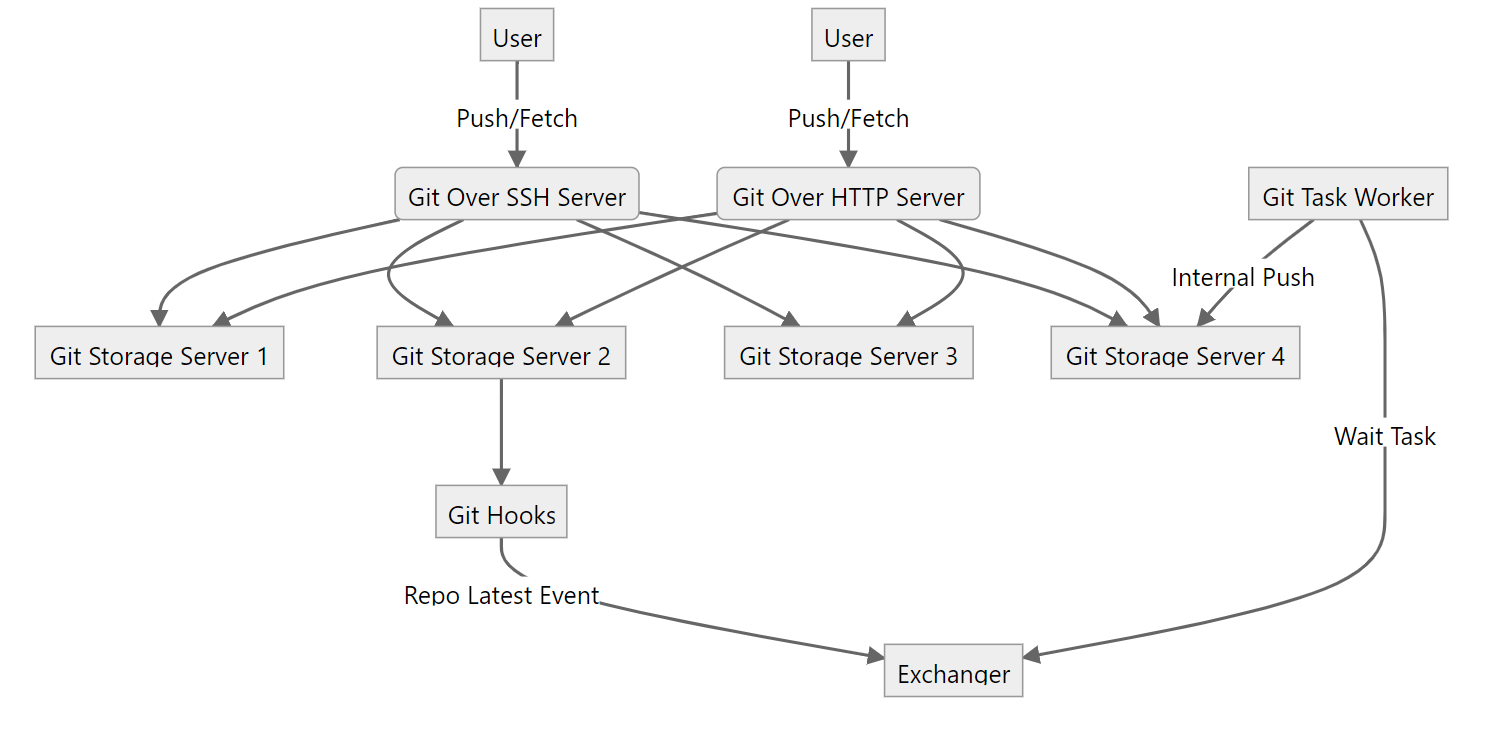
存储库实现了实时同步,还需要有一种机制保证存储库数据一致,Github 的方案是循环哈希校验和,而我的方案是使用 BLAKE3 计算引用哈希,原理很简单,就是将存储库的引用按字典排序计算哈希值,哈希值一致意味着两个存储库的引用一致,引用一致存储库克隆获得的数据也就是一致的,两个存储库肯定一致啊。
这里主从同步高可用如果支持将读取请求转发到其他副本而不仅是主副本,那么这种情况就叫读写分离高可用(简称读写分离),读写分离的好处就是对于特别活跃的存储库能够提供更高的并发。当然无论是看似简单的主从同步,还是复杂的读写分离,内里考虑的细节并不少,环环相扣,需要对整个代码托管架构有一个清晰的认识。
实施类似 Github Spokes (DGit is now Spokes) 一样的多写高可用要复杂一些,主要难点是要支持同时写入到多个副本,要做到这一点需要实现一些约束性条件:
- 写入到多个副本的前提是多个副本的数据是一致的,Github 使用了三阶段提交协议先判断是否可以写入,写入的前提就是服务正常,存储库一致。
- 存储库的引用更新应该是事物的,也就是说可以回滚事务,这样在写入到其中一个节点失败后,其他的节点上实时回滚。这一点可以考虑使用原子更新引用,可以修改 git receive-pack 源码增强实现该功能。
- 代码托管平台常常使用 git 钩子实现一些功能,这些钩子的操作是否等幂,也就是说,钩子的执行结果在不同的副本上退出码必须一致,如果不同副本中执行钩子不做区别,我们要保证钩子中请求 API 授权的结果一致,避免内部服务故障照成影响,执行 post-receive 钩子产生动态或者触发 WebHook 时需要进行消息去重,避免多次执行。当然还有一种方案就是只执行一次钩子,然后使用协调机制将钩子的结果广播到其他副本,共同进退。
- 存储库在不一致,或者从停机中恢复后,多写高可用依然需要考虑存储库的同步,以保证不同节点的一致性。
要设计好高可用,应该实现一套良好的故障检测机制,合理的方案多种,第一种可以用专门的服务检测磁盘是否可用,服务是否联通,出现故障时标记不可用,恢复后直接标记为正常即可。还可以通过学习,将前端服务与存储节点通信的错误采集分离,进行健康评估,在节点故障时将其下线。两者都需要不断的汲取经验,故障的错误标记往往是灾难性的,Github 就出现过这样的事故,给其声誉带来了一定的影响。
无论是主从同步还是读写分离以及实时多写架构,都需要给存储库创建多个副本,这就意味着存储空间的消耗加倍,每个存储库有一个副本,存储空间的消耗就要增加一倍,两个副本就增加两倍,所以在设计高可用系统的时候就需要考虑到经济因素对架构的影响,这也是国内代码托管行业高可用架构发展并不顺利的原因之一。另一方面,运行良好的代码托管平台实施高可用也不是一蹴而就的,这也和平台的历史债务和规模息息相关,太急迫的话反而容易在设计和实施的过程中出现纰漏。
在开发多写高可用系统时如果能修改 git 源码来优化一些细节,这将对架构设计有更大的好处,设计上留有余地,环节可以优化,比如通过修改 git 源码实现主动非侵入数据流的原子更新要比拦截请求模拟原子更新要好得多,在 receive-pack 中修改执行钩子的逻辑,也更容易符合读写系统的设计。然而现实往往并不能令人满意,国内代码托管平台几乎都缺乏足够的人手参与 git 贡献,长期的偏向业务的研发也没有足够的能力反思 git 代码托管平台的架构。这样的现状也就阻碍了国内代码托管行业的创新,平台也很容易陷入苦苦跟随的地步。
5. 思考
代码托管早期有 SourceForge,我刚刚工作时,构建的 Clang On Windows 便是发布在 SourceForge 上分发的,现在已经好几年没登录 SourceForge 了,Git 的发展说快不快,说慢也不慢,但终归是流行起来了,Github 把其他平台施虐干净,真有点所向披靡的样子,国内得益于政策环境,Github 想进来并不容易,国内也就有了一番天地,做到 Github 那样的规模并不容易,做到 Github 那样的技术更不容易,罗马不是一天建成的,需要很多人的持续努力罢了。
6. 引用
- Git Repository Layout
- Git Internals - Git Objects
- Git Virtual File System Design History
- Git at Scale
- 《性能,可扩展性和高可用 - 大型 Git 代码托管平台的关键问题》
- 《探讨 Git 版本控制系统的若干问题 - 2020 版》
- 《探讨 Git 代码托管平台的若干问题 - 2019 版》
- 《服务端 Git 钩子的妙用》
- 《基于 Git Namespace 的存储库快照方案》
- 《构建恰当的 Git SSH Server》
- 《Git 原生钩子的深度优化》
- Monorepos in Git
- Scaling monorepo maintenance
- Scaling Mercurial at Facebook
7. 感谢
之前写过多篇 Git 相关原理介绍的文章,也写过探讨代码托管平台架构的文章,虽然文章数量多,但比较离散,行文中偶尔夹杂的代码如果没有阅读源码的背景也不容易理解,总之并不是尽善尽美,尽管如此,我一直以来也没有想法写一篇这样的文章,最近受相关人士的邀请在公司内做了一次题为《代码托管从业者 Git 指南》的分享,也准备了讲义,分享完后,相关人士又帮忙安排了一篇外宣稿子,于是就写下了这篇文章,也算是对从业多年的一个技术总结吧。粗鄙文章分享,如有错误可以在 https://github.com/fcharlie/fcharlie.github.io/issues 指出,感谢朋友们的阅读,特别感谢相关人士促成这次分享。
Let me know what you think of this article on twitter @sinopre!