性能,可扩展性和高可用 - 大型 Git 代码托管平台的关键问题
前言
2019 年我写了 《探讨 Git 代码托管平台的若干问题 - 2019 版》 从技术栈,功能,伸缩性等方面比较了业内一些代码托管平台(或者开源项目),是第一次对行业的反思。随着事物的不断变化,人们的认识也是不断发展的,在吸收了新的知识,做出了新的实践,换了新的工作后,我对于代码托管平台的认识也有了更多的想法。在实现大型代码托管平台时,性能,可扩展性,高可用 这些问题不断的跃入眼前,随着时机成熟,我觉得很有必要粗略的探讨一些这类问题的解决方案,分享给感兴趣的人。
关键问题的定义
对于分布式系统而言,可扩展性(也可称之为 伸缩性),高可用,性能 是制约平台发展的关键性问题,也就是说只有在解决这些问题后才能够支撑更大的用户规模,服务更多的用户,创造更多的社会价值,对于代码托管平台而言,这也是一个普适的道理。
系统具备可扩展性则意味着系统可以横向扩展,能够支撑更大的用户规模,存储更多的数据。
系统支持高可用则意味着用户几乎能够随时访问系统,系统出现软硬件故障时依然能够继续给用户提供完整的或者有限的服务,避免服务完全降级。
提升系统的性能则有助于加快数据处理,提高用户的访问速度,改善用户操作体验。
Git 的关键性能
Git 代码托管平台与常规的 Web 服务有着很大的不同,Git 要比其他 Web 服务需要更多的 CPU 计算时间和 IO 读写速度,这也是我经常给一些客户,开发人员传递的信息。我们回忆一下 Git 存储结构,目录结构通常如下:
| 路径 | 目录\文件 (D\F) | 描述 |
|---|---|---|
| objects | D | 松散对象和包文件 |
| refs | D | 引用,包括头引用,标签引用,和远程引用 |
| packed-refs | F | 打包的引用,通常运行 git pack-refs (git gc 也是如此) 后产生 |
| HEAD | F | 当前指向的引用或者 oid,例如 ref: refs/heads/master |
| config | F | 存储库的配置,可以覆盖全局配置 |
| branches | D | - |
| hooks | D | 请查看 Documentation/githooks.txt |
| index | F | git index file, Documentation/technical/index-format.txt |
sharedindex.<SHA-1> |
F | - |
| info | D | 存储库信息,哑协议依赖 info/refs |
| remotes | D | - |
| logs | D | 运行 git log 可以查看提交记录 |
| shallow | F | - |
| commondir | D | - |
| modules | D | 子模块的 git 目录 |
| worktrees | D | 工作目录,更新后的文档与 git 多个工作目录有关 |
Git 在未打包的时候,把引用按照引用文件的方式存储在 refs 目录下,比如分支 dev 对应的引用文件名就是 refs/heads/dev,分支的 CommitID 16 进制值就是 refs/heads/dev 的文件内容。打包后,分支文件名和文件内容就会在使用字典排序后存储到 packed-refs 文件中,文件格式如下:
# pack-refs with: peeled fully-peeled sorted
0b7bd57e0d9d9a549c9ca03cd9d9cc4ae5de25dc refs/heads/dev
这里有一点需要注意,引用文件的优先级要高于 packed-refs,由于文件系统的文件时间是能够通过系统调用或者 API 修改,因此要靠文件时间去比较优先级并不可靠。
Git 真正的对象存储在 objects 目录,当使用 git add 命令添加时,会使用 zlib 将文件压缩后生成松散的对象,这种对象会在松散目录中使用 16 进制作为文件名分片存储,16 进制对象 ID 的前两个作为目录名,后 38(SHA256 62)作为文件名,比如对象 24b603b4d0de4a52d76ec6e780e4a22836e427cd 的松散路径肯定是 objects/24/b603b4d0de4a52d76ec6e780e4a22836e427cd。git 还支持将松散对象打包到 pack 文件以提高存储库读取性能,其中的细节在这里也就不详述了,有兴趣的可以查看:Git pack format。
讲完这些我们可以知道,Git 通常需要直接读写文件系统,如果文件数量特别多的时候,势必会带来巨大的文件 IO 压力,举个例子,Linux 内核存储库目前的对象数目是 7870377,如果这些对象全部以松散对象的方式存储,占据的文件系统空间为(Linux 文件系统文件占据空间一般为 4K 的整倍数),那么磁盘占用是 30 GB 左右,如果对象大小大于 4KB 这个体积要更大一些,因此 Git 引入了打包机制提高存储库读取性能。我们知道 Linux 读取文件首先需要打开文件句柄,使用 open,然后调用 read,如果一次性读不完还需要调用更多的 read,最后还需要调用 close 关掉文件句柄。7870377 个文件的读取也至少需要 23611131 直接系统调用,内核态用户态的切换也将耗费非常多的 CPU 时间。
有些人提出疑问,是否可用使用分布式文件系统或者对象存储,这里我们如果使用分布式文件系统,这么多小文件,文件的元数据累计起来,耗费的数据包真的不少,除了直接系统调用,分布式文件系统的套接字系统调用也不会少的。前面也提到 git 会使用打包机制将引用或者对象打包到对应的文件中以提高存储库读取效率,但对于代码托管平台而言,不断有用户读写存储库,松散对象和未打包的引用数量肯定不会少,使用分布式文件系统或者对象存储库很容易遇到性能问题,以国内外的厂商的失败为鉴,Git 目前使用物理磁盘或许是更好的选择。
优化压缩解压
前文我们知道,Git 使用了 zlib 库将文件按照 deflate 算法压缩的变体 zlib。压缩算法的效率对存储库的操作性能影响很大,我们将文件纳入版本管理需要使用 deflate 压缩,检出查看存储库文件需要使用 deflate 的解压缩方法 inflate 解压对象,在服务器上,用户推送代码到远程服务器,计算用户的贡献度也需要 inflate 解压对象然后按行比较,用户通常不会注意到通过网页查看文件之前也需要 inflate 对象,下载压缩包需要 inflate 然后 deflate (或者 GZ),在线提交需要 deflate。我们如果能优化 Git 的压缩解压效率则很有可能提高 git 操作性能。
与其他压缩库相比,zstd 除开许可证的宽松,使用广泛有非常大的优势,压缩算法 deflate 本身并不具备很大的优势,deflate 的压缩比和压缩速度都不是最优。目前压缩率压缩比综合较好的压缩库(算法)是 facebook 开源的 zstd,zstd 开发者给 zstd/zlib 做过一些基准测试如下:
For reference, several fast compression algorithms were tested and compared on a server running Arch Linux (
Linux version 5.5.11-arch1-1), with a Core i9-9900K CPU @ 5.0GHz, using lzbench, an open-source in-memory benchmark by @inikep compiled with gcc 9.3.0, on the Silesia compression corpus.
| Compressor name | Ratio | Compression | Decompress. |
|---|---|---|---|
| zstd 1.4.5 -1 | 2.884 | 500 MB/s | 1660 MB/s |
| zlib 1.2.11 -1 | 2.743 | 90 MB/s | 400 MB/s |
| brotli 1.0.7 -0 | 2.703 | 400 MB/s | 450 MB/s |
| zstd 1.4.5 –fast=1 | 2.434 | 570 MB/s | 2200 MB/s |
| zstd 1.4.5 –fast=3 | 2.312 | 640 MB/s | 2300 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 560 MB/s | 710 MB/s |
| zstd 1.4.5 –fast=5 | 2.178 | 700 MB/s | 2420 MB/s |
| lzo1x 2.10 -1 | 2.106 | 690 MB/s | 820 MB/s |
| lz4 1.9.2 | 2.101 | 740 MB/s | 4530 MB/s |
| zstd 1.4.5 –fast=7 | 2.096 | 750 MB/s | 2480 MB/s |
| lzf 3.6 -1 | 2.077 | 410 MB/s | 860 MB/s |
| snappy 1.1.8 | 2.073 | 560 MB/s | 1790 MB/s |
| Compression Speed vs Ratio | Decompression Speed |
|---|---|
 |
 |
如果能换一种现代的压缩算法,Git 或者能够给人眼前一亮,但是切换压缩算法会破坏 Git 的兼容,很多时候可能是得不偿失的,因此不可行。除了切换压缩算法,我们还可以改进 zlib 自身,zlib 作为一个历史悠久的开源算法压缩库,需要支持各种平台,具备很好的通用性,但是却没有利用好平台的特性进行优化,缺少注册 SIMD 这样的指令优化,因此,开源界则有一些优化方案,比如 Intel 提供了一个针对 Intel CPU 优化的 zlib 版本,也有一群人维护了 zlib-ng 项目,该项目为 zlib 添加了 x86/arm/s390/power SIMD 指令支持,chromium 也提供了一个 zlib 优化版本 chromium zlib,性能相当不错。除此之外还有一个速度非常快的 deflate 实现 libdeflate,遗憾的是,libdeflate 并不支持流式压缩,这就很难被 git 使用。
解决拉取时的性能问题
Git 代码托管平台需要提供的核心能力至少包括推送和拉取,拉取代码包括 git fetch 和 git clone,我们只讨论简单的智能传输(smart)协议,不讨论 Wire(v2) 协议,以 git fetch(HTTP) 为例:
- 客户端请求
GET /path/repo.git/info/refs?service=git-upload-pack - 服务端返回引用列表
- 客户端按引用发送已存在的、需要的 commit 信息
- 服务端按照所需、已存在的 commit 清点对象,打包返回给客户端
我们逐一分析,在这个过程中会存在哪些性能问题,当客户端需要服务端的引用列表时,服务端上的 git 要将存储库中的引用及其 commit 一一返回给客户端,我们知道,git 的引用存储在存储库的 refs目录下按文件存储,每一个引用对应一个文件,也可以打包存储到 packed-refs 中,如果存储库引用较少,分支较少,那么这通常不是问题,但是,如果存在一个像 Windows/Chrome 这样的项目,几万个分支,如果这些分支都未打包到 packed-refs,在服务发现的过程我们就会发现,open() 系统调用就有几万个,几十上百个请求过来都是几百万的系统调用了,这还能不影响性能吗?解决这个问题的方法 git 早已经提供了,packed-refs,将引用打包存储到一个文件中,作为代码托管平台而言该怎么做呢?定期 GC,使引用被打包。
如果引用数目较多,这也就意味着一次性传输的数据较多,但这些数据并不一定全部是用户需要的,引用发现还是一股脑的返回了。如何解决这个问题,2018 年 5 月 Git Wire Protocol 出现了,Wire 协议可以使用 ls-refs 命令获得仅需的引用信息。
在这个流程中,如果 git 存储库的对象比较多,那么清点对象的时间可能非常长,之前清点对象的原理如下:
- 列出本地所有分支最新的一个commit
- 列出远程所有分支最新的一个commit
- 两者进行比较,只要有不同,就意味着分支发生变动
- 每一个发生变动的commit,都清点其中具体变动的子目录和文件
- 追溯到当前commit的父节点,重复第四步,直至本地与远程的历史一致为止
- 加总所有需要变动的对象
早期清点 Linux 内核源码这样的仓库需要 8 分钟,这太慢了能解决吗? Github 贡献了 Git Bitmap 通过空间换时间解决了这个问题,具体的实现细节可以阅读相关博客和规范。对于代码托管平台而言,及时更新 Git 版本,配置好 bitmap 设置如 repack.writeBitmaps=true 通常能获得更好的体验。
缩短推送耗时
对于 Git 推送,目前依然使用的是智能传输协议,其流程如下:
- 客户端请求
GET /path/repo.git/info/refs?service=git-receive-pack - 服务端返回引用列表及其他能力信息(包括原子更新等等)
- 客户端清点打包需要上传的对象
- 服务端接受对象包,解包,更新引用,返回更新结果。
随着用户需求的多样化,平台提供的特性越来越多,为了实现这类功能(比如针对 Git 做细粒度的权限控制,开发规范检查),我们通常是非侵入式的通过钩子实现,而通过钩子实现必然有一定的逻辑,这也会带来一定的时间消耗,比如,平台限制用户推送较大的文件,那么在钩子中就需要找出此次推送是否包含大文件,在之前的博客中,我就分享过如何优化钩子使其能够更快的找到大文件 《Git 原生钩子的深度优化》,这篇文章中还包含了钩子的其他场景优化。
其他场景的优化
有些平台,比如 Gitee 为企业级用户提供了存储库的快照功能,望文生义,快照就是每一次都做一次备份,那这么做会不会存在什么性能问题?如果每次都是全量的拉取存储库,大量数据带来的不仅仅是网络流量还有磁盘空间,CPU 时间消耗,因此在 2018 年,我就分享了 《基于 Git Namespace 的存储库快照方案》,通过名称空间变换实现 Git 存储库快照功能,通过优化极大的减少数据的传输。
比较两个存储库的数据是否一致,意味着它们拥有共同的对象,同样的引用,同样的 HEAD,但这种指标过于绝对,应当排除存储库中已经脱离版本控制的对象,如果存储库完整,我们只要一一比较存储库的引用是否一一对应且对象 ID 一致即可,如果我们需要跨机器比较,那么比较的市场一定和引用发现的时间和传输引用的时间相关,引用发现的时间不能缩短,那么我们可以优化引用传输的时间,我们通过在存储库中按照引用排序计算 BLAKE3 的哈希值,计算完毕后通过传输 BLAKE3 的哈希值比较两个存储库是否一致,这样就能优化存储库的比较。
性能优化的总结
故不积跬步,无以至千里;不积小流,无以成江海。Git 代码托管平台的性能提升也不是一蹴而就的,通常是一点一点的攻坚经过日积月累,也不一定被人所知,用的人不觉得差便已经足够。
解决平台的扩展性
与超级计算机相比,普通的计算机基本上是一个 CPU,内存大小较小,磁盘 IO 速度较低,而代码托管平台基本上是运行在这些普通计算机上的,这就意味着,从硬件层面来看,当计算机数量有限时,能够支撑的用户规模是有限的。而对于一个平台而言,如何基于整个平台实现其扩展性,为更多的用户提供服务,存储更多的存储库,这是实现大型 Git 代码托管平台的关键问题。
首先,服务器的存储是有限的,这一个问题毋庸置疑,随着硬件的不断发展,在代码托管平台中,我们可以为一台服务器挂载数 TB 的硬盘,更大的硬盘能够存储更多的内容,但是我们需要注意,硬盘的容量的价格曲线并不是线性的,因此,容量巨大的硬盘可能价格并不经济,另外单块硬盘的读写速度也是有限制的,因此早期,人们可以将多块硬盘挂载到一台机器以提高容量,但通常提高的容量比较有限。
分布式文件系统的歧途
人类的历史是螺旋发展的,有对的尝试也有错误的尝试,而代码托管的发展历史也是如此,现在我们谈论 Git 代码托管服务的可扩展性的时候,一般不建议使用分布式文件系统,前面我们已经讲了 Git 对于 IO/CPU 的要求很高,分布式文件系统并不能解决这个问题,冒然尝试该方案,很容易出现大的事故。2014 年,笔者加入开源中国,最初的工作是在 Git 代码托管平台实现兼容的 SVN 接入,彼时,为了支撑更多的存储库,当时的 Gitee(当时没有品牌,域名为: git.oschina.net)使用的是 NFS 将多台机器挂载到一台机器上,在这台机器上提供读写存储库的能力,按照现在的知识背景评价这种方案,我们能轻易的发现其中的问题:通过 NFS 读写文件的效率低于本机读写,NFS 存在缓存导致文件锁不能及时删除,git 的计算压力集中在 NFS client 端….. 当年的情况正是如此,后来为了解决这一问题,开发团队选择 ceph 文件系统替换 NFS. 这次变更堪称灾难性的,周末上线周一宕机,在海量 git 小文件面前,ceph 不堪一击,后来开发团队不得不回退到 NFS 方案。
分析各个大型代码托管平台的技术栈,我们也没发现任何平台坚守分布式文件系统,也就没有分布式文件系统在 Git 上运用的成功案例。
无论是 NFS 还是 Ceph 都无法解决 Git 的存储扩展问题,后来 Gitee 研发团队决心使用分片解决平台的扩展性,刚好我也完成 SVN 接入后工作,便参与进来,经过几年演进架构演进,才成了今天中国第一大代码托管平台。虽然已经离开了 Gitee,但这几年做的这些工作还是有很大的价值。
Git 的分片技术
要实现 Git 平台的可扩展,对资源进行合理的分片尤为重要,分片的方案很多,采用不同的分片方案往往与当时的技术背景相关,也与当时的认知背景相关,在 Gitee 最开始分片时,开发团队选择的是基于用户(Team),也就是 namespace,这种策略的缺点很明显,创建仓库不能直接创建到空闲机器,负载并不均衡。后来 Gitee 切换到按照存储库分片,试图解决之前方案的不足,但由于历史包袱,这一过程持续了很长的时间。
我们在考虑 Git 的分片技术时,应该将存储库的真实路径与存储库 URL 分离,否则,在提供用户改名或者存储库改名,存储库转移的时候带来不必要的麻烦。
为了管理好这些存储库,我们除了需要做好分片还需要为其提供完整的配套维护方案,比如存储库分布在不同的存储节点,有的节点负载较高,有的节点较为空闲,这个时候我们可以将一些存储库迁移到空闲的机器,因此我们需要开发一套合适的迁移方案,另外在新建存储库的落点选择上,还需要设计一个周到的落点机制,让新建的存储库尽量落点到负载较轻的节点。
如果平台提供了 fork 这样的功能,那么对节点之间的存储库克隆同步等操作也应该实现内部传输机制,尽量避免通过公网传输消耗网络流量。
公共存储库的优化
公共 Git 代码托管平台很容易遇到一些热点问题,比如体积巨大的活跃存储库,在提供 fork 功能之后,这些存储库可能存在数量巨大的 fork 数。为了避免 fork 带来的海量存储问题,我们可以使用 git 的对象借用实现 fork 功能,以降低存储消耗。
当然公共存储库的优化是一个非常复杂的问题,在本文中就不再赘述了。
代码托管平台的高可用
对于平台而言,服务的高可用是平台的重要质量指标,服务稳定运行,故障较少,这也是用户优先选择的因素之一,无论是代码托管公有云还是私有化部署,用户对高可用的需要总是存在的。而实现 Git 代码托管平台的高可用一直是业内的一大挑战,尽管 Git 代码托管平台数量并不少,但大多数平台并未有有效的高可用解决方案,拥有解决方案的平台对其中的细节也语焉不详。这样看来,Git 代码托管高可用像极了一个黑盒。我在研究代码托管平台高可用方案时也耗费了很多精力,所幸有了自己的见解。
作为一个职业生涯与 Git 息息相关的开发者,如果让我选择一个职业上比较有成就感的事,目前我可能会说是为前东家的 Gitee 设计和实现的 Git 代码托管平台分布式读写分离架构。这一方案是目前比较经济划算的商用方案,据了解 Gitee 为了支持华为鸿蒙操作系统开源,专门将相应的存储库存储到读写分离机器组中,另外还有国内某大型国有银行内部使用了该方案实现其代码托管的高可用。
随着认识的不断深入,我对实现 Git 代码托管平台高可用的认知也不断加深,架构设计也有了新的想法,反思以往总总,放眼未来,把我所知与诸君共享,也希望有人能够有灵光一现,也算得上前赴后继,共创繁华。
基于事件驱动型读写分离
我们谈论到高可用,通常能够想到的方案是主从实时同步,这种机制也能被 Git 使用以实现代码托管的高可用。比如 Gitee 的分布式读写分离架构还是腾云扣钉的高可用架构本质上都是此类,二者的由于硬件和基础架构的差异,因此对高可用的需求重点并不相同,因此在叫法和实现上有一些区别,比如 Gitee 是一个公共的代码托管平台,用户规模巨大,请求量多,因此需要通过读写分离分散负载,读写分离架构需要解决的就是这种场景,而腾云扣钉则更多的为私有化服务,公有云规模稍低,保证数据的可靠性反而是重中之重,高可用的设计也就没有考虑到读写分离。(关于 Gitee 的架构之路,有兴趣的伙伴可以查看 Gitee 负责人周凯的公开课 《技术深解码 - Gitee 代码托管平台之架构洞察》)
Git 读写分离的逻辑大致是将存储库的副本存储在多个节点,节点可以交叉存储,也可以按机器划分,然后一个节点作为主节点或者一个存储库副本作为主副本,用户的写入请求将被转发到主节点或者主副本,在存储库一致时,其它节点或者其他副本将能够处理用户的读取请求,也就是拉取(git pull/git fetch),这里有一点需要注意,主节点和主副本也能处理读取请求。现实世界的经验告诉我们,通常读取请求的数量要远高于写入去请求,在 Git 世界我们也面临这样的难题,因此提高 Git 读取能力也是读写分离的初衷之一。存储库副副本要提供读取首先的保证数据和存储库主副本一致,这就要求我们实现内部同步服务,这个服务通常只在内网运行,为了提高效率我们通常使用 git:// 协议,内部传输服务还需要提供默认分支同步机制,以保证用户修改存储库默认分支后能够及时更新。除了要实现内部同步服务,我们还需要实现一套存储库一致性校验算法,随着引用数量的增长,直接比较引用是否一致花费的代价也不断增长,我通常会选择使用类似 BLAKE3 这样现代的哈希算法通过将一一比较引用转变为比较哈希值,这样一来也就不必要传输大量的网络数据了。该架构一个简单的流程图如下:
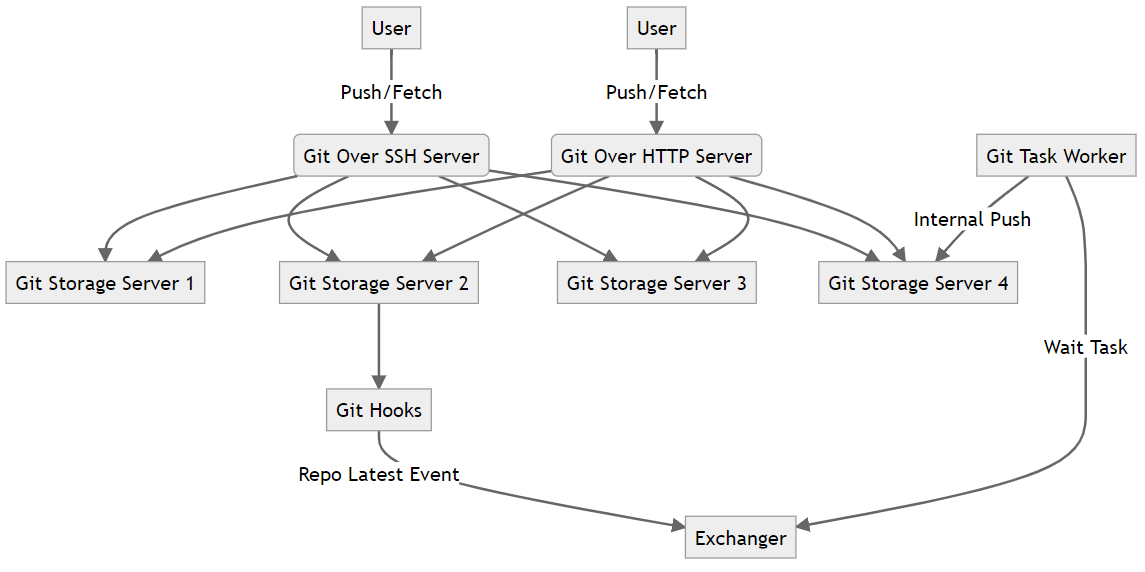
在此架构中,用户在推送代码后,会触发钩子创建 Latest 事件,然后事件关联的任务被存储到队列,然后被 Git 后台服务消费,将存储库同步到其他副本,完成后消除存储库的 Latest 状态。我将此种读写分离称之为基于事件驱动型读写分离,状态由事件产生,因事件消除。在这个事件驱动的模型中,我们可以看到,存储库的同步是异步的,基于 Git 的使用场景来看,读多写少意味着我们总能得到足够收益,但从数据一致性上来说,这种妥协还是需要我们在保证存储库数据安全上需要添加一些补救措施,比如推送事件会产生存储库 Latest 状态,出现 Latest 状态意味着存储库的 Slave 副本变得不可读,必须由同步服务消除 Latest 后才能写取,同样的在 Master 发生故障时存储库也只能在没有 Latest 状态时才能在新的 Master 节点上为用户提供读写。
这种方案如果其他副本存储库不提供读取,那么就会退化成单纯的高可用,但是从技术的复杂度上将,单纯的高可用与支持读写分离的高可用复杂度相差无几。
实时性多写高可用设计
我们假设一下,如果用户请求时同时写入多个副本,那么是不是不用考虑同步的问题,是不是也能实现更好的一致性?这个问题也是我反复思考的问题。我们知道,git 在功能上比较孱弱,需要通过钩子增强,如果不考虑到钩子的影响,两个完全一样的存储库,在接收到一样的数据,git 版本都兼容时,那么预期的结果将是一致的,也就是两个相同的存储库数据都被更新到相同的状态,也就是说这是等幂的。如果把钩子考虑进来,那么现状就会发生变化,钩子在不同存储库上执行可能有先后顺序,也许会通过网络请求 API,这些操作实际上已经破坏了等幂性。那么解决问题的思路就出现了,一种是绕开等幂约束,一种是让推送过程回复等幂。
等幂性的破坏可以从几个维度去分析,比如我们在增强 Git 功能时,会使用 Git Hooks,Git Hooks 可能需要调用 API,受网络影响,API 调用可能失败,如果一个节点上的钩子 API 调用成功,另一个执行失败,这就会导致执行钩子输出的结果不再相同,也就不能算作是等幂的。另外 API 服务在处理各个节点的钩子请求,可能并不是同时性的,而是有先后,如果在两个节点请求的中间,用户修改了一些设置,那么获得的数据也就不再一致,那么钩子的数据结果也就可能不再相同。那么不同节点上的副本也就会出现数据差异,存储库变得不再一致。好了,我们看一看服务器上有哪些钩子,在服务端,Git 2.29 支持的钩子如下:
| 钩子名 | 参数运行细节 | 使用场景 | 备注 |
|---|---|---|---|
pre-receive |
该钩子没有参数,一次推送执行一次,从标准输入中按照 <old-value> SP <new-value> SP <ref-name> LF 接收每一个引用的变更,失败导致整个推送失败 |
由于该钩子具备环境隔离机制,因此可以更好的被运用到大文件和存储库体积限制功能上,当然也能被运用到保护分支等功能中 | |
update |
该钩子参数为 <ref-name> <old-value> <new-value>, 每更新一个分支执行一次,失败导致当前引用更新失败 |
该钩子可以被用户实现保护分支,邮箱检测,以及只读目录等功能 | |
proc-receive |
proc-receive | 主要目的是场景是支持 Gerrit 工作流 | 阿里巴巴开发者贡献 |
post-receive |
运行细节与 pre-receive 相同,但运行结果不影响存储库更新。 | 主要用于存储库推送事件的发生 | |
post-update |
参数与 update 相同 | 主要用于通知,不影响存储库更新结果,但平台基本上没有使用 | - |
reference-transaction |
标准输入读取 <old-value> SP <new-value> SP <ref-name> LF 引用更新事务钩子 |
- | - |
push-to-checkout |
- | - |
我们在使用钩子实现相关功能时,流水线也被拉长了,新增的环节可能出出现各种各样的异常,我们辛辛苦苦追求的等幂也就只能另辟蹊径了。
我们在实现实时多写的问题时,一种解决方案是绕过等幂限制,我们在执行钩子的时候,仅在一个节点(这里用功能节点代称)以完整功能执行钩子,其他节点上,我们则将钩子转变为观察者,观测功能节点的执行结果,进行一致性协商后共同进退。
在这个过程中,我们为了提高执行结果的一致性,可以引入 balance_atomic 这样的原子更新机制,主动的为存储库开启原子更新,还需要实现一个 balance hook 将原子更新的结果同步协商共同进退,这样在推送时,一个节点失败,则所有的节点也都会执行失败,建议的 git 补丁如下:
diff --git a/builtin/receive-pack.c b/builtin/receive-pack.c
index bb9909c52e..bca3843f00 100644
--- a/builtin/receive-pack.c
+++ b/builtin/receive-pack.c
@@ -60,6 +60,7 @@ static int report_status;
static int report_status_v2;
static int use_sideband;
static int use_atomic;
+static int use_balanced_atomic;
static int use_push_options;
static int quiet;
static int prefer_ofs_delta = 1;
@@ -226,6 +227,11 @@ static int receive_pack_config(const char *var, const char *value, void *cb)
return 0;
}
+ if (strcmp(var, "receive.balancedatomic") == 0) {
+ use_balanced_atomic = git_config_bool(var, value);
+ return 0;
+ }
+
if (strcmp(var, "receive.advertisepushoptions") == 0) {
advertise_push_options = git_config_bool(var, value);
return 0;
@@ -1844,6 +1850,8 @@ static void execute_commands_atomic(struct command *commands,
goto failure;
}
+ // TODO: check balance-update hook
+
if (ref_transaction_commit(transaction, &err)) {
rp_error("%s", err.buf);
reported_error = "atomic transaction failed";
@@ -1951,7 +1959,7 @@ static void execute_commands(struct command *commands,
(cmd->run_proc_receive || use_atomic))
cmd->error_string = "fail to run proc-receive hook";
- if (use_atomic)
+ if (use_atomic || use_balanced_atomic)
execute_commands_atomic(commands, si);
else
execute_commands_non_atomic(commands, si);
此方案需要设计合适的分布式信号量机制(基于强制同步的 Redis 也可以使用实现的信号量机制),钩子感知信号灯标识,继续或者退出。
另一种方案是,钩子在执行过程中,不通过网络而是通过环境变量传递获得功能权限等设置的信息,然后只需要轻度的协商即可,而 post-receive 这样的钩子事件绑定到唯一的 ID,然后插入到事件队列时去重,但此种方案的缺陷是可扩展性不强,给钩子新增功能,需要操作多个环节。
我们需要注意 Git 实时同步多写系统,如果支持多数节点写入成功这种特性而不是全部节点写入成功才算成功,那么,我们在设计系统的时候也就必须将前面的高可用方案完整的引入进来,上述的多写系统每一个环节也需要修补,这样一来,系统的复杂性大大的增加了。
用户代码的可靠性和安全性
除了存储库多副本,我们还可以实现存储库快照功能,这样一来用户的代码安全就是非常可靠的,遇到节点故障,其他节点上的存储库副本能够继续提供服务,遇到存储库被恶意删除,使用存储库快照可以快速恢复。存储库快照功能可以参考:《基于 Git Namespace 的存储库快照方案》。
除了存储库本身的安全能提高用户代码的可靠性,平台做好一些其他的功能也能避免用户的数据丢失,被窃取。比如使用强度和计算较快的密码哈希算法 argon2 加密用户密码,在设计 Token 系统的时候设计细粒度的权限机制,HTTP 协议使用最新的 TLS1.3,SSH 使用 ED25519 这样的加密算法,或者 RSA 使用更高的位数。另外还要设计合理的运维机制,避免出现删库跑路事故。
研发困境
作为一个专门的代码托管研发人员,我认为在解决代码托管平台的这些关键问题并不是难乎其难,相反,这些问题从技术上都可以设计出系统的解决方案。然而事实总是与理想相悖,研发上的困境使得各种美好的设想停留纸面。既没有足够的人来添砖加瓦,又没有足够的耐心来步步为营,也没有破釜沉舟改天换地的勇气,徒呼奈何。
终
日复一日,想了又想,写了又写,天黑了天亮了,写下一篇粗鄙文章。
Let me know what you think of this article on twitter @sinopre!