探讨 Git 版本控制系统的若干问题 - 2020 版
前言
自 2014 年大学毕业以来,我一直从事代码托管相关工作,工作的内容和 git 相关,期间积累了很多心得体会,这大概是一般的 git 使用者很少会感知到的,一直以来,我也想将这些见解分享给大家,之前我写过《探讨 Git 代码托管平台的若干问题 - 2019 版》,这篇文章主要偏向代码托管平台的开发,与普通开发者存在一定的距离,快一年过去了,我又有了新的体会,写一篇关于 Git 版本控制系统的若干问题也就有了动机。
Git Flow 与 Git 的表与里
在使用 Git 进行团队协作的时候,网络上铺天盖地的推荐方案是使用 Git Flow 工作流,什么是 Git Flow?Git Flow 由 Vincent Driessen 在 2010 年,在文章 A successful Git branching model 中提出,Atlassian 也写了一篇文章:Gitflow Workflow 对其有个介绍,大致流程图如下:
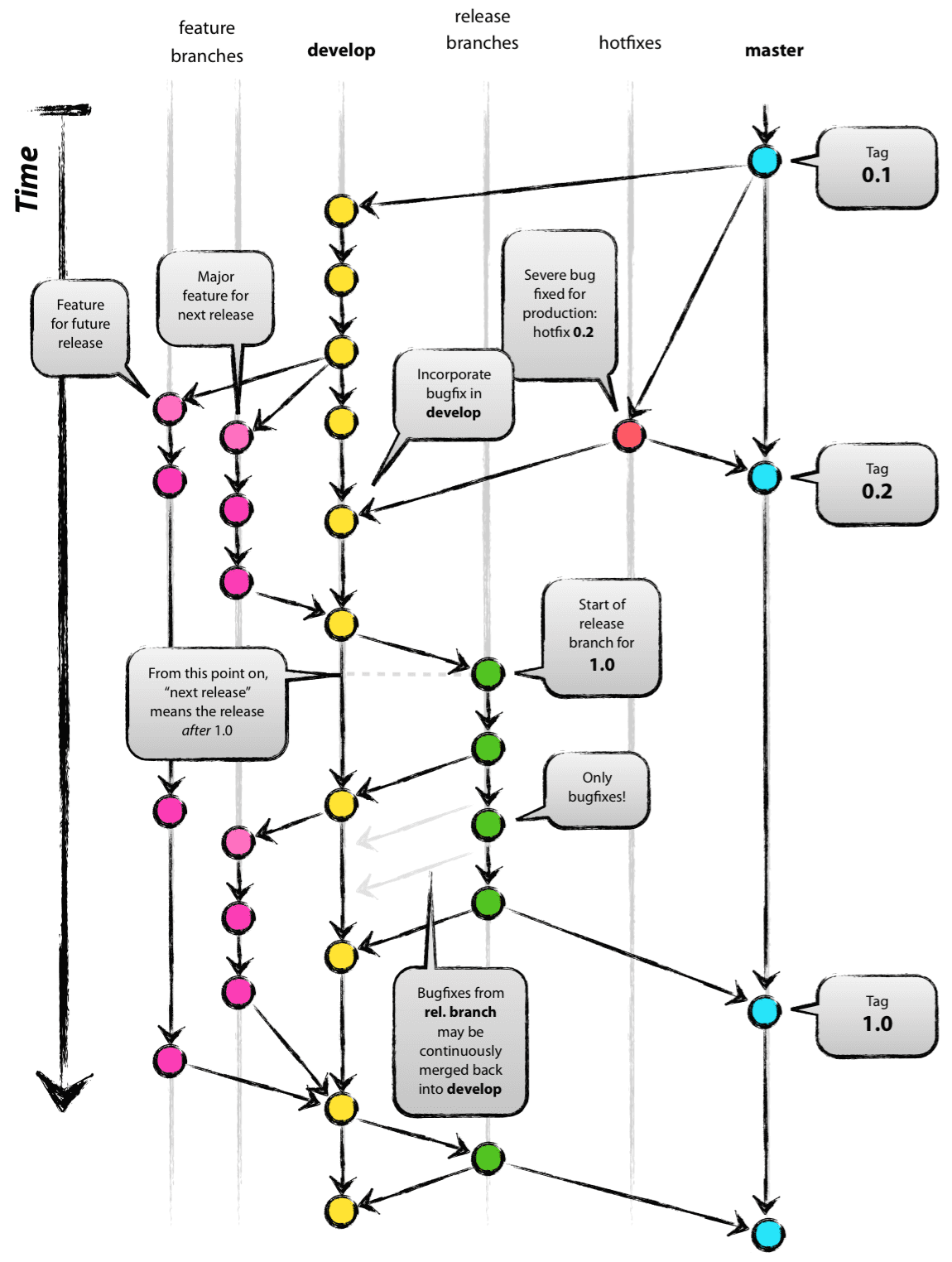
简而言之,就是在 develop 分支快速迭代,将 master 作为稳定分支,使用 feature 分支添加新的功能。说实话,我并不是很喜欢 Gitflow,Git 的分支和 SVN 这样的版本控制系统相比,足够轻量,比如 SVN 新建分支需要拷贝分支,而 git 就是创建对某个 commit 的引用即可,这样看来,git 中的分支都是均权的,Gitflow 的概念就像话术了,比如我们完全可以把稳定分支命名未 stable 或者 release,把快速迭代分支命名为 trunk。实际上有一些开发者明确反对 Git Flow,比如 George Stocker 就写过 Please stop recommending Git Flow!,而 Vincent Driessen 本人在今年也认为 Git flow 是一种教条。
Note of reflection (March 5, 2020)
This model was conceived in 2010, now more than 10 years ago, and not very long after Git itself came into being. In those 10 years, git-flow (the branching model laid out in this article) has become hugely popular in many a software team to the point where people have started treating it like a standard of sorts — but unfortunately also as a dogma or panacea.
During those 10 years, Git itself has taken the world by a storm, and the most popular type of software that is being developed with Git is shifting more towards web apps — at least in my filter bubble. Web apps are typically continuously delivered, not rolled back, and you don't have to support multiple versions of the software running in the wild.
This is not the class of software that I had in mind when I wrote the blog post 10 years ago. If your team is doing continuous delivery of software, I would suggest to adopt a much simpler workflow (like GitHub flow) instead of trying to shoehorn git-flow into your team.
If, however, you are building software that is explicitly versioned, or if you need to support multiple versions of your software in the wild, then git-flow may still be as good of a fit to your team as it has been to people in the last 10 years. In that case, please read on.
To conclude, always remember that panaceas don't exist. Consider your own context. Don't be hating. Decide for yourself.
在 git 的世界中,我们理解了分支和最终纳入版本控制的文件是如何组织的,就能更好的思考应该使用什么样的工作流。Git 的存储结构太多文章和文档有过说明,这里详述繁琐且没必要,简单的说一下,在 refs 目录或者 packed-refs 存储了 git 存储库的引用信息,引用名(refs/heads/master)与特定的 commit ID 映射,引用只有唯一的 commit ID,commit ID 却可以跟多个引用关联,比如我们使用 git checkout -b 或者 git switch -c 就可以基于当前的分支的 commit 创建新的分支。分支是包含特定前缀 refs/heads/ 的引用。
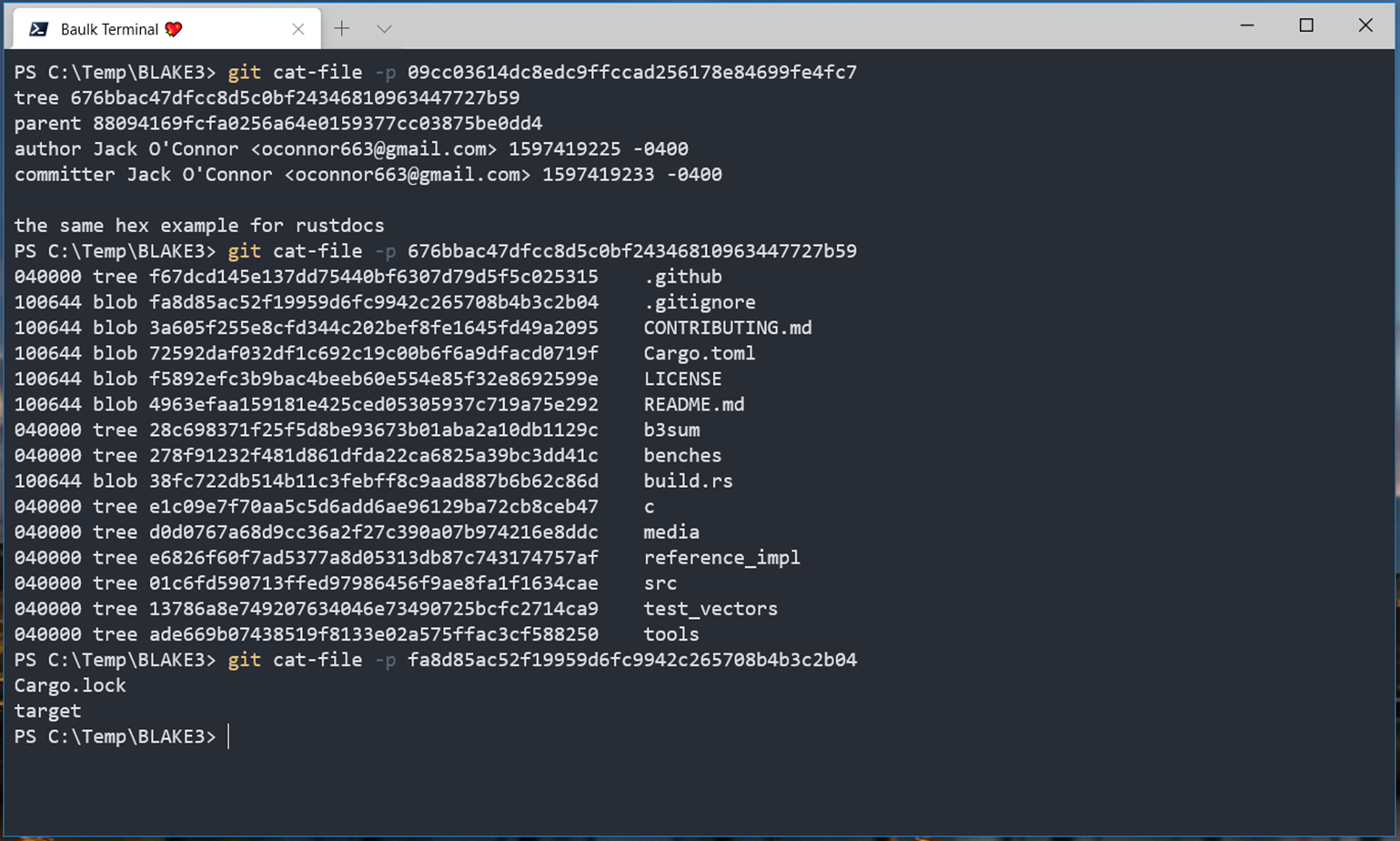
Git commit 是 git 对象的顶层数据,在 git 对象中,包含 commit,tree,blob 这样的对象,一个 commit 有一个 tree,零个或者多个 parent commit,我们可以使用特定的命令查看 commit 的内容:
# https://github.com/BLAKE3-team/BLAKE3.git
git cat-file -p 107f5c089f356334ee4abaeeca8c31704661f37d
其内容可能如下
tree 107f5c089f356334ee4abaeeca8c31704661f37d
parent f2005678f84a8222be69c54c3d5457c6c40e87d2
author Jack O'Connor <jack.oconnor@zoom.us> 1593462857 -0400
committer Jack O'Connor <jack.oconnor@zoom.us> 1593463133 -0400
stop being a jerk and add the context string to test_vectors.json
Git tree 对象存储了存储库的目录结构,tree 的格式为特殊的二进制格式,我们同样可以用 git cat-file 查看 tree 对象。
git cat-file -p 107f5c089f356334ee4abaeeca8c31704661f37d
tree 对象的 pretty 输出如下:
040000 tree c44c5f00bbfd67a6e5597292b811055fa5f90034 .github
100644 blob fa8d85ac52f19959d6fc9942c265708b4b3c2b04 .gitignore
100644 blob 3a605f255e8cfd344c202bef8fe1645fd49a2095 CONTRIBUTING.md
100644 blob 720e9a4ab4976211fe78ea44681150460cf9ed81 Cargo.toml
100644 blob f5892efc3b9bac4beeb60e554e85f32e8692599e LICENSE
100644 blob c9f8bd517d5e8da7b178cf15804ea46ddb9e35c9 README.md
040000 tree 6391f865df6b772571669f0193cfa84eb4a0ad40 b3sum
040000 tree 278f91232f481d861dfda22ca6825a39bc3dd41c benches
100644 blob 38fc722db514b11c3febff8c9aad887b6b62c86d build.rs
040000 tree aa2ca2f0ab338bdf2effa1ad2333f09f70025a94 c
040000 tree d0d0767a68d9cc36a2f27c390a07b974216e8ddc media
040000 tree e6826f60f7ad5377a8d05313db87c743174757af reference_impl
040000 tree 9118932371d77760db085bfc7341b41128486eb1 src
040000 tree 13786a8e749207634046e73490725bcfc2714ca9 test_vectors
040000 tree ade669b07438519f8133e02a575ffac3cf588250 tools
在 git 中 blob 存储的就是文件本身,其格式为 type SPACE OCT_LENGTH NUL $FILE_CONTENT,存储在磁盘的内容是使用 Deflate 压缩的,文件名在压缩前由 SHA1 计算文件头和文件内容得来,也就是说使用 Deflate 解压缩后,使用 SHA1 就可以获得与之匹配的 Blob ID,我们可以通过 git cat-file 查看文件内容
git cat-file -p fa8d85ac52f19959d6fc9942c265708b4b3c2b04
Cargo.lock
target
这里分享一个基于 Golang 编写的 Blob 细节查看演示程序(Gist):
package main
import (
"compress/zlib"
"crypto/sha1"
"encoding/hex"
"errors"
"fmt"
"hash"
"io"
"os"
"strconv"
)
// git blob view
// BlobViewer todo
type BlobViewer struct {
w io.Writer
zr io.ReadCloser
fd *os.File
h hash.Hash
}
// NewBlobViewer new blob viewer
func NewBlobViewer(p string, w io.Writer) (*BlobViewer, error) {
fd, err := os.Open(p)
if err != nil {
return nil, err
}
return &BlobViewer{fd: fd, w: w, h: sha1.New()}, nil
}
func (bv *BlobViewer) readUntil(delim byte) ([]byte, error) {
var buf [1]byte
value := make([]byte, 0, 16)
for {
if n, err := bv.zr.Read(buf[:]); err != nil && (err != io.EOF || n == 0) {
if err == io.EOF {
return nil, errors.New("invalid header")
}
return nil, err
}
bv.h.Write(buf[:])
if buf[0] == delim {
return value, nil
}
value = append(value, buf[0])
}
}
// Header Lookup header
func (bv *BlobViewer) Header() error {
raw, err := bv.readUntil(' ')
if err != nil {
return err
}
fmt.Fprintf(os.Stderr, "object type is: \x1b[34m%s\x1b[0m\n", raw)
if raw, err = bv.readUntil(0); err != nil {
return err
}
size, err := strconv.ParseInt(string(raw), 10, 64)
if err != nil {
return err
}
fmt.Fprintf(os.Stderr, "object size: \x1b[34m%d\x1b[0m\n", size)
return nil
}
//Lookup blob details
func (bv *BlobViewer) Lookup() error {
zr, err := zlib.NewReader(bv.fd)
if err != nil {
return err
}
bv.zr = zr
bv.Header()
mw := io.MultiWriter(bv.w, bv.h)
_, _ = io.Copy(mw, bv.zr)
return nil
}
// Close close blob viewer
func (bv *BlobViewer) Close() error {
if bv.zr != nil {
bv.zr.Close()
}
fmt.Fprintf(os.Stderr, "Hash: %s\n", hex.EncodeToString(bv.h.Sum(nil)))
if bv.fd != nil {
return bv.fd.Close()
}
return nil
}
func main() {
if len(os.Args) < 2 {
fmt.Fprintf(os.Stderr, "usage: %s blob-id\n", os.Args[0])
os.Exit(1)
}
bv, err := NewBlobViewer(os.Args[1], os.Stdout)
if err != nil {
fmt.Fprintf(os.Stderr, "open: %s error %v\n", os.Args[1], err)
os.Exit(1)
}
defer bv.Close()
if err := bv.Lookup(); err != nil {
fmt.Fprintf(os.Stderr, "lookup: %s error %v\n", os.Args[1], err)
os.Exit(1)
}
}
git 的内里还是十分简单的,无论分支名怎样变,内部的组织结构并没有显著差别,是一种简单的轻量的分支形式,因此,我们在选择 Git Workflow 时,或许应该解放思想,实事求是,遵循自己的业务模型。
像操作系统,比如 Windows,Linux 内核,FreeBSD,以及 LLVM,GCC 这样的大型软件,需要定期发布新版本,然后给新版本执行一个生命周期,开发流程类似于 Trunk-Release-Tag 在 Git 语义下,我们认为是 Master-Release-Tag,即在主干分支上不断演进,定期从主干创建特定的 Release 分支,然后 Release 不添加新的功能,只修复 BUG,按照发布路线图和实际测试情况发布新的 Release (也就是 Tag)。一般的大型软件均会采取这种演进模型。
对于 Web 服务而言,类似 Git Flow 的模型确实是合适的选择,快速演进能够及时修复问题和增加新的功能,但如果服务不仅仅提供给公有云用户,那么还是需要考虑到版本化,Git Flow 不是灵丹妙药,需要开发者按照实际需求来。
Git 的错付
git 是个优秀的版本控制系统也避免不了用户的不恰当使用,最后反而导致用户体验的下降。如果 Git 是个人,估计会大声说 “臣妾做不到啊”,这就是 Git 的错付了。
Git: 我不做网盘
作为代码托管的业内人士,我遇到过非常多的使用 Git 当网盘,存储二进制,做图床的场景,这种使用经常给平台带来了很高的 QPS,也会可能导致用户的存储库超出体积限制。要解释这个问题,我们要理解 Git 是基于文件快照的,当使用 git 将文件纳入版本控制时,git 实际上将文件内容原样合成 blob 压缩后存储,此时,比如我们使用 git 管理一个 50MB 大小的文件,那么,修改 20 次后,如果按照 50% 的压缩率,那么,光这个文件的历史记录累计的体积也就达到了 500MB,这非常可观。
Git 存储文件会被压缩,如果做图床,不做优化的情况下,每次下载图片时,都需要解压 Blob,这实际上会给平台带来性能问题,消耗掉计算资源。另外,图片格式通常是一种压缩格式,按照香农信息论,特定的字节数所承载的信息是有上限的,也就是说,文件是不能被无限压缩的,因此,Git 存储被压缩的文件实际上效果并不明显,反而浪费 CPU。为了避免图床的场景影响平台的负载,大多数 Git 代码托管平台都会使用 RAW 缓存,以避免这类请求拖累系统。当网盘和图床场景类似。
LFS: 我不会压缩
为了解决大文件存储问题,Github 推出了 Git LFS 管理 Git 大文件,避免大文件频繁更改导致存储库体积过度膨胀。但 Git LFS 并不是万能灵药,一些不合适的使用场景可能会导致反常的预期。
比如我最近接触到一个场景下,有开发者使用 Git LFS 管理 JDK8 二进制,将大多数 Java 命令和 Jar 等文件使用 LFS 追踪,如果完全使用 Git 管理,存储库的体积是 175MB,这就意味着下载的数据量为 175MB。但 Git LFS 并不会压缩文件,下载数据时,使用 HTTP GET 请求依次下载,我们查看 lfs/objects 目录的文件大小为 366MB,而查看 LFS 文件数量,大致是 199 个,那么,需要发送的 HTTP 请求为 199 次,这种场景下,势必会导致 LFS 服务器 QPS 过高,用户下载数据缓慢。
回过头来看,Git LFS 的使用是有边界的,只要在特定的条件下,才具备相应的优势,否则会降低用户体验,造成客户端和服务端的双输。
Git: 我就这样了
Git 虽然强大,但有一些功能也是不容易做到,比如完整的目录权限控制,尽管我们告诉私有化客户,可以做到目录级别权限控制,但那仅仅只能做到写入控制,而无法做到读取控制。另外 Git 还不能真正的做到类似 SVN 一样的部分检出,尽管目前增加了部分克隆功能,但在协议上,仍然做不到 SVN 那种层度。
作为一个代码托管平台开发者,有时候需要和用户解释为什么不那么做也挺累的。
Git 的重新思考
Git 虽然强大,但并不完美,比如哈希算法选择的是不安全的 SHA1,压缩算法选择的是 Deflate,如果创建个新的版本控制系统确实可以好好思考了。
对象存储的重新思考
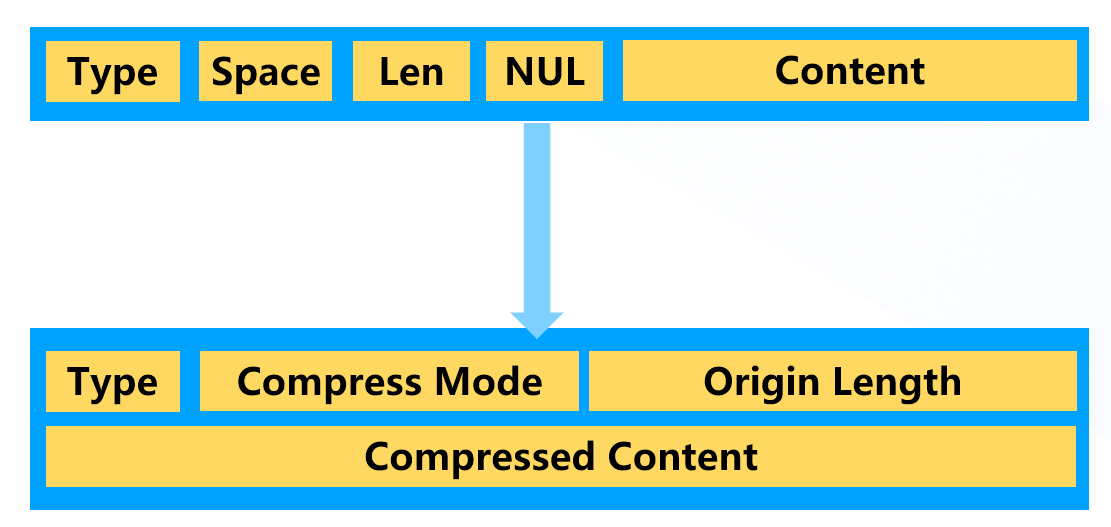
Git 存储文件的对象叫做 Blob,Blob 格式的设计比较简单,格式如下图上侧,Type 的类型用户标识是 Blob 还是 Commit 还是 Tree。数据按图所示拼接计算出哈希值后,将哈希值作为对象的 ID,然后使用 Deflate 压缩,这种机制并不是很完美的,比如不能按原样存储,文件不能无限压缩,因此,git 并不适合存储压缩文件,二进制文件。
今年以来,我曾参与 minizip,libzip,archiver 的 ZIP 格式对 Zstd 压缩算法的支持,了解到 ZIP 中的 Store 存储机制,ZIP 可以将其他 ZIP 文件按照 Store 的方式原样存储到新的 ZIP 文件中,这无疑可以避免重复的压缩文件,浪费 CPU。因此,理想中的 Git 对象存储变成了下图下侧,文件的哈希不包含文件的长度,类型和压缩算法,仅与文件的原始内容相关。
Git 选择的 Deflate 并不是一个优异的压缩算法,无论是压缩率还是压缩速度都不是最佳的,如果在重新设计 Git 的时候,Zstd 应该是一个更好的选择。下表是 Zstd 与 Zlib(Deflate) 压缩比和速度的一个对比。
| Compressor name | Ratio | Compression | Decompress. |
|---|---|---|---|
| zstd 1.4.5 -1 | 2.884 | 500 MB/s | 1660 MB/s |
| zlib 1.2.11 -1 | 2.743 | 90 MB/s | 400 MB/s |
| brotli 1.0.7 -0 | 2.703 | 400 MB/s | 450 MB/s |
| zstd 1.4.5 –fast=1 | 2.434 | 570 MB/s | 2200 MB/s |
| zstd 1.4.5 –fast=3 | 2.312 | 640 MB/s | 2300 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 560 MB/s | 710 MB/s |
| zstd 1.4.5 –fast=5 | 2.178 | 700 MB/s | 2420 MB/s |
| lzo1x 2.10 -1 | 2.106 | 690 MB/s | 820 MB/s |
| lz4 1.9.2 | 2.101 | 740 MB/s | 4530 MB/s |
| zstd 1.4.5 –fast=7 | 2.096 | 750 MB/s | 2480 MB/s |
| lzf 3.6 -1 | 2.077 | 410 MB/s | 860 MB/s |
| snappy 1.1.8 | 2.073 | 560 MB/s | 1790 MB/s |
下图是压缩解压的对比(来源于 Zstandard):
| Compression Speed vs Ratio | Decompression Speed |
|---|---|
 |
 |
哈希算法的选择
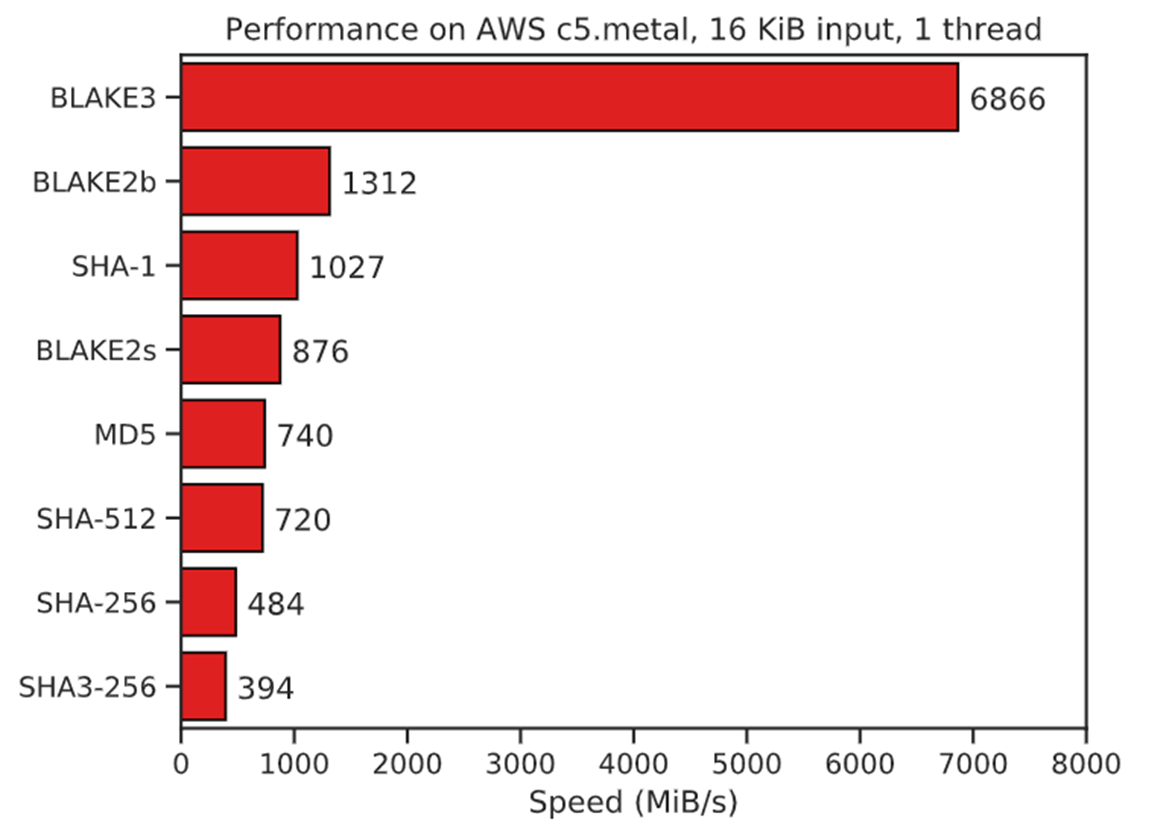
自从 SHA1 被破解以来,Git 选择新的哈希算法便提上了日程,经过多次讨论,Git 开发者最终选择了不是最佳的 SHA256。SHA256 是最佳选择吗?不见得,我写过一个 Kisasum 的压缩工具,比较了 SHA256,BLAKE3,KangarooTwelve,SHA3,SM3 等压缩算法,SHA256 的速度位于下游,BLAKE3 官方有个测评,如下:
使用 Measure-Command 命令测评 SHA256 和 BLAKE3 计算 224MB 的 sarasa-gothic-ttf-0.12.14.7z ,实测速度差距如下:
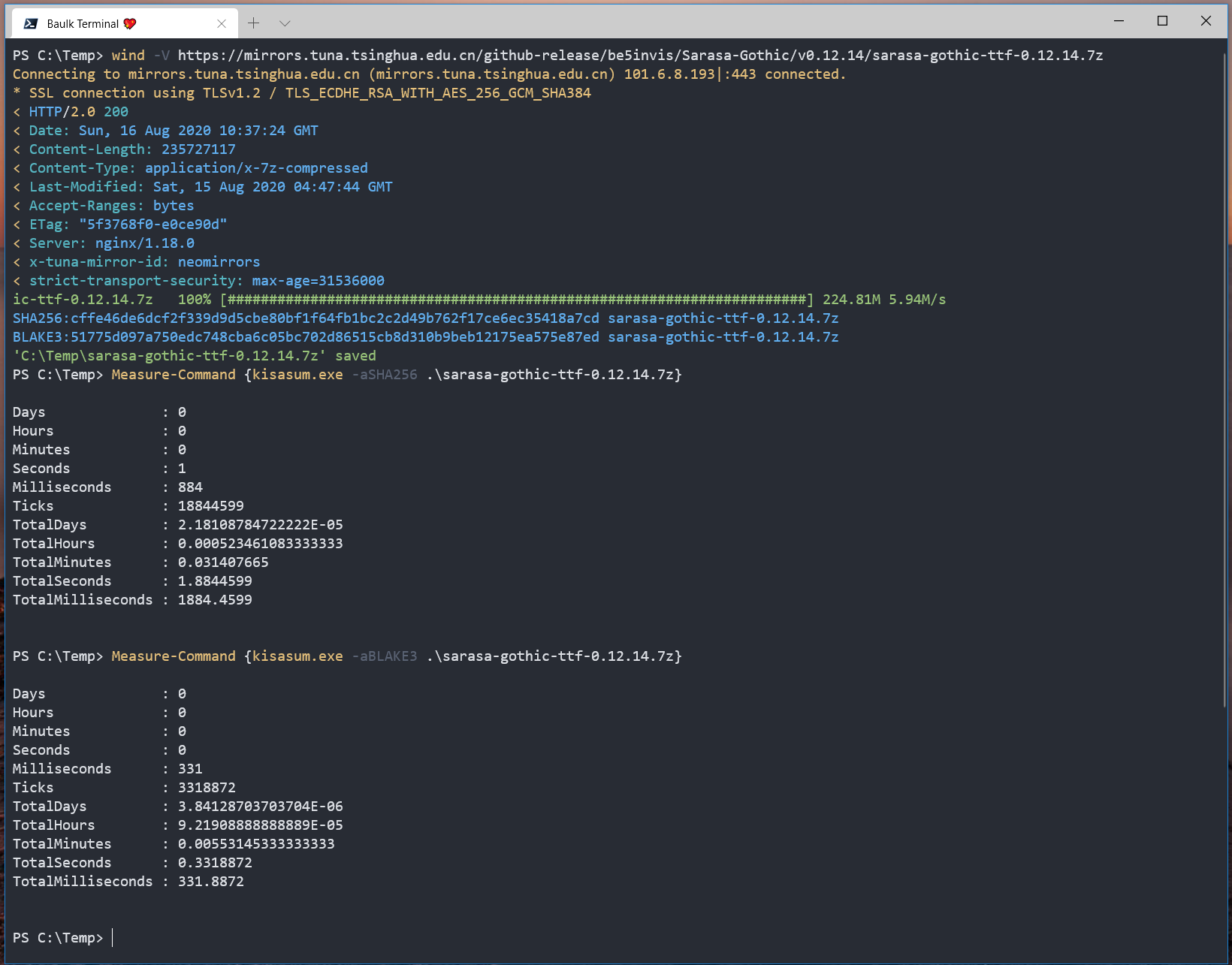
SHA256 耗费了 1884ms,BLAKE3 耗费了 331ms,差距已经有 5 倍了,而且这里 Kisasum 的 BLAKE3 没有使用多线程,差距还可能更大。如果让我选择哈希算法,我可能选择 BLAKE3 或者 KangarooTwelve。
版本控制系统的下一步
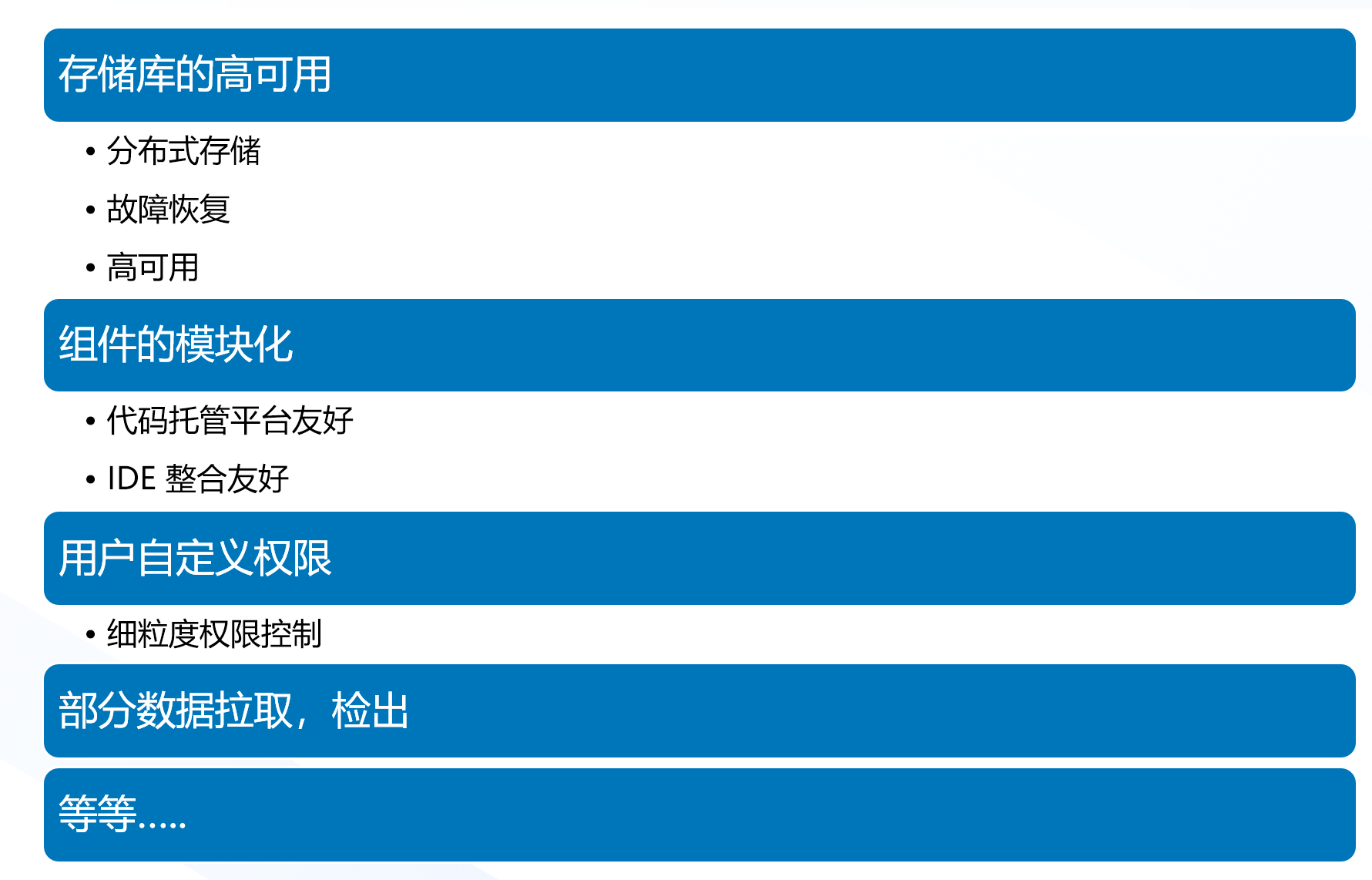
优秀的版本控制系统是 DevOps 生态中重要的一环,除了提供版本控制的功能之外,还要有利于 DevOps 功能整合,下图是我对版本控制系统下一步增强的期许,而现实情况下,Git 实现下面的功能比较复杂,并不是那么方便,从业人员也经常不得不曲线救国。
最后
Git 已经诞生十五年了,Git 的取代者是谁?
Let me know what you think of this article on twitter @sinopre!